
一、简介
1.1 简介
Elasticsearch 是一个高性能,基于lucene得全文检索服务,是一个分布式restful风格得搜索和分析引擎,也可以作为NoSQL数据库使用
- 对lucene做了扩展
- 原型环境和生产环境可以无缝切换
- 能够水平扩展
- 支持结构化和非结构化数据
1.2 应用场景
- 日志搜索和分析、时空检索、时序检索、智能搜索等场景
- 检索的数据类型复杂:如果需要查询得数据有结构化数据、半结构化数据、非结构化数据等,elasticsearch可以对以上数据类型进行清洗、分词、建立倒排索引等一系列操作,然后提供全文检索能力
- 检索条件多样化:全文检索条件可以包括词或短语
- 边写边读:写入的数据可以实时进行检索
1.3 生态圈
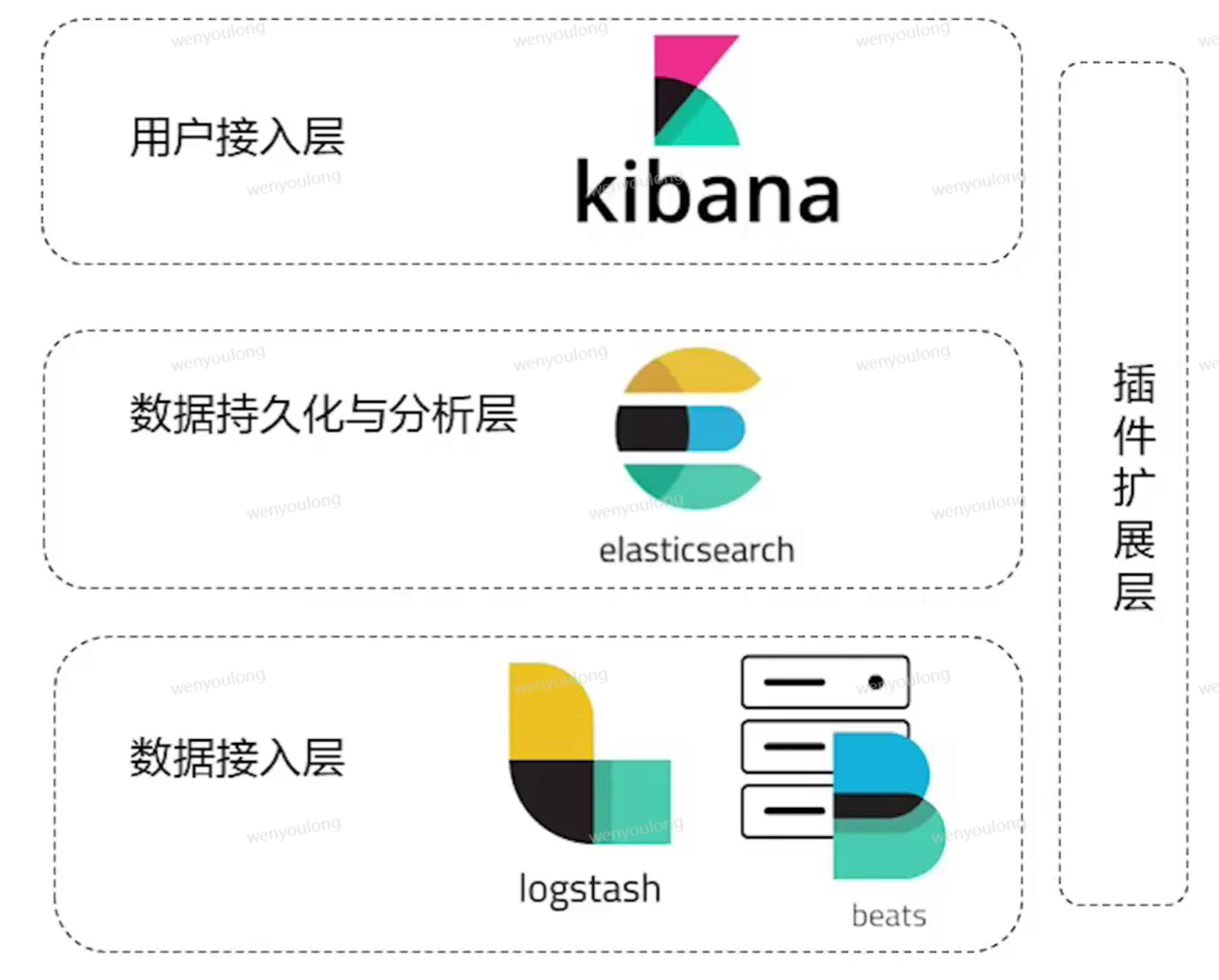
ELK/ELKB提供了一整套解决方案,并且都是开源软件,之间相互配合使用,高效得满足了很多使用场景
二、基本概念
2.1 es基本概念
2.1.1 index 索引
index是es中的一个逻辑命名空间,可以理解为MySQL中的数据库。
2.1.2 type 类型
类型是索引的逻辑类别/分区,同一索引中可以存储不同类型的文档。可以理解为数据库里的表,es7以后的版本已删除type
2.1.3 document 文档
文档是可以编制索引的基本信息单元,可以理解为表里得行数据。
2.1.4 mapping 映射
映射,用来约束字段类型
2.1.5 fields 字段
相当于数据库表中的字段。
2.2 es集群基本概念
2.2.1 cluster
代表一个es集群,集群中可以有多个节点,其中一个为主节点,这个主节点可以通过选举产生
2.2.2 node
es节点,一个节点就是一个elasticsearch实例
2.2.3 master
主节点可以临时管理集群级别的一些更改,例如新建或删除索引、增加或移除节点等,主节点不参与文档级别得变更或搜索,该主节点再流量增长时,不会成为集群的瓶颈
2.2.4 shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分不到不同的节点上,es提供了将索引进行数据分片得功能,创建索引时,只需定义所需的分片数即可
2.2.5 replicas
索引的数据分片存储在不同的服务器上,可能会发生故障导致分片不可用,Elasticsearch可以创建分片副本,可以在创建索引时为每个索引定义分片和副本数,创建索引后,可以随时动态更改副本数量,但不能更改分片数量
- 提供系统容错率,当某个节点某个分片损坏或丢失时,可以从副本中恢复
- 提高es查询效率,es会自动对搜索请求进行负载均衡
2.3 核心概念
- recovery es数据的恢复和数据重新恢复,es加入或退出节点时,会根据机器的负载对索引分片重新分配,挂掉的节点重启时也会进行数据恢复
- gateway es索引快照的存储方式,es默认先把索引存储放到内存中,当内存满了时再持久化到本地磁盘,gateway对索引快照进行存储,当es集群关闭又重启时,就会从gateway中读取索引备份数据。es支持多种类型额gateway,有本地文件系统,分布式文件系统,hadoop的HDFS和amazon的s3云存储服务
- transport 代表es内部节点或集群与客户端的交互方式,默认内部都是通过TCP协议进行交互,同时它支持http协议、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)
三、Elasticsearch架构
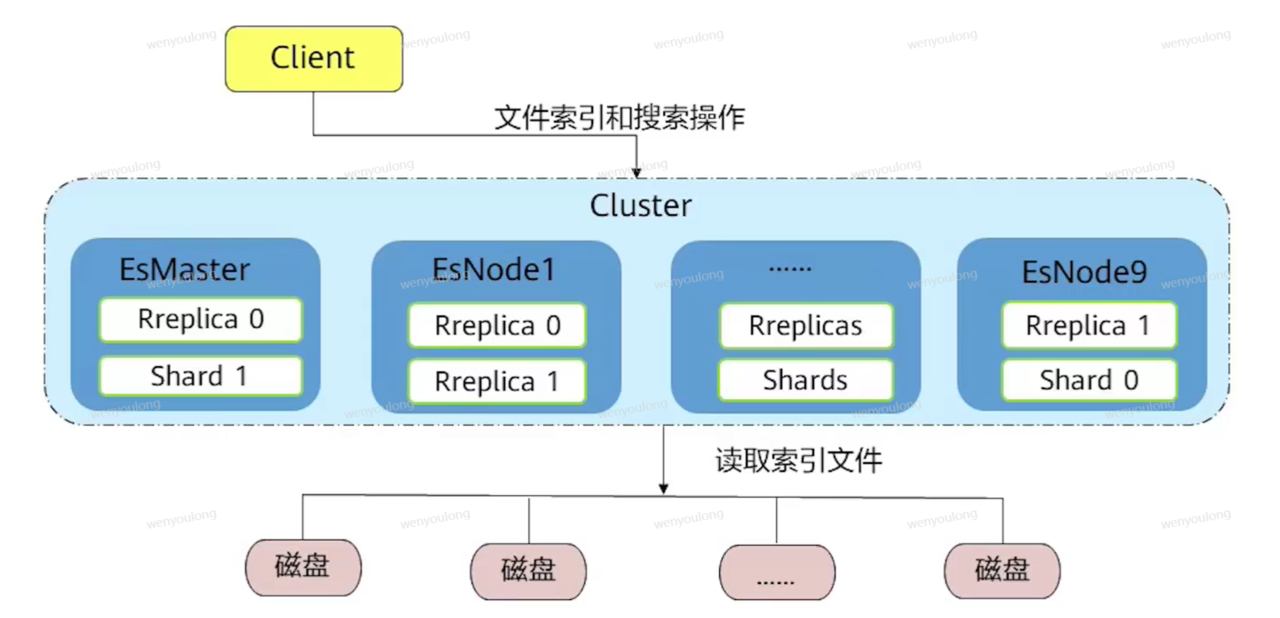
3.1 系统架构
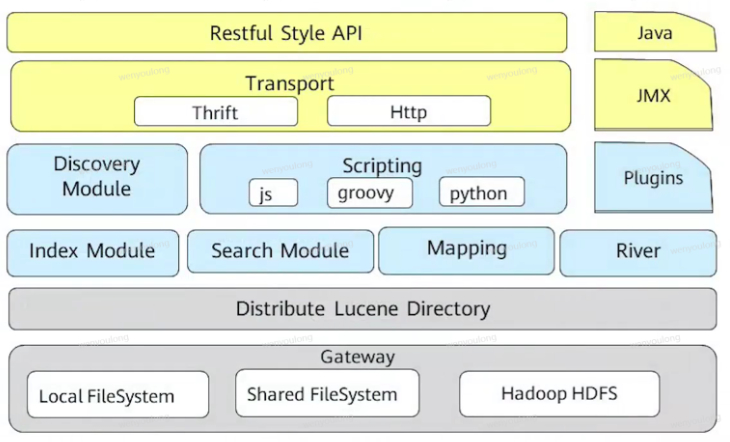
3.2 内部架构
- gateway 存储索引文件,可以采用本地文件,分布式系统文件,云存储方式存储
- distribute lucene directory 分布式lucene目录由lucene管理,负责对文件目录的读写以及更改
- index module 数据索引
- search module 数据搜索
- mapping 告诉elasticsearch索引数据得字段属性,以及如何进行索引
- river 是一个扩展性组件,表示数据源
- discovery module 用于集群节点管理,选取主节点
- scripting es所支持的脚本
- plugins es得可扩展性插件
- transport es跟客户端进行通讯的方式,支持多种协议,如http
- jmx elasticsearch监控功能
- java es使用java开发
- restful api 方便上层组件调用es
四、关键特性
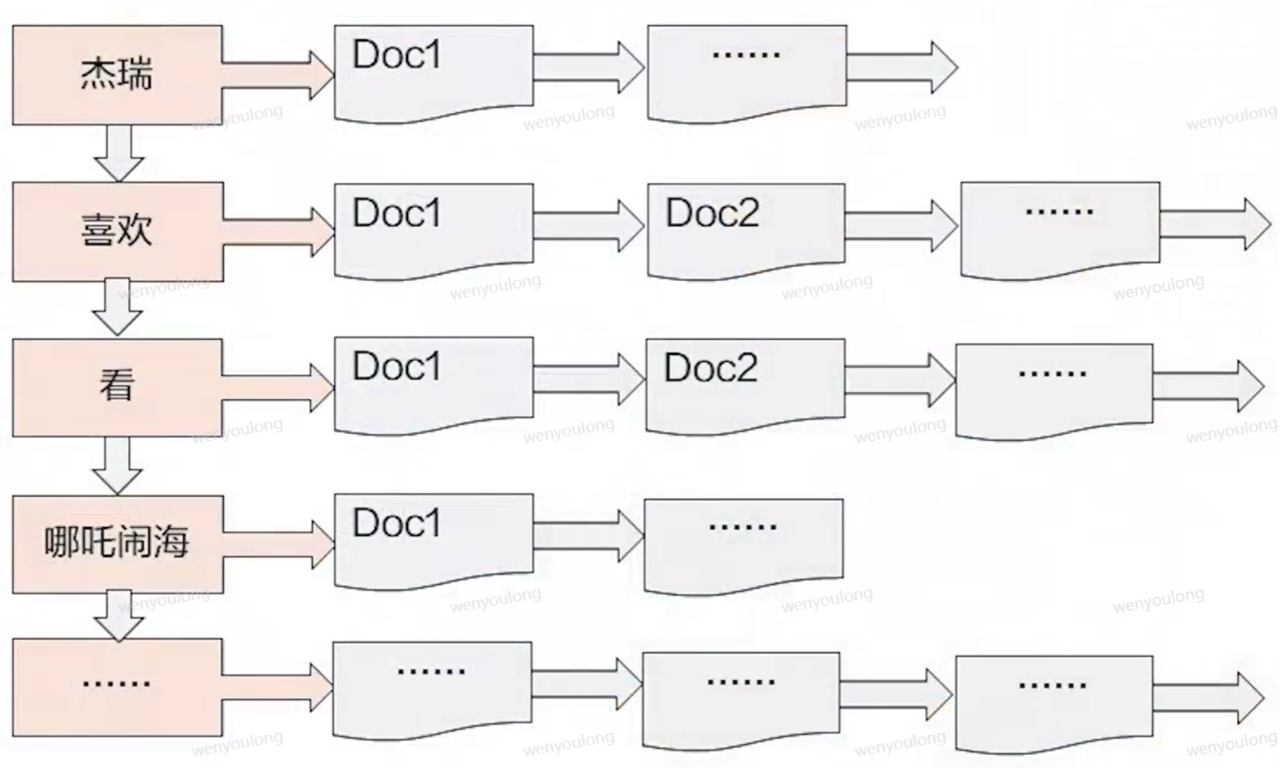
4.1 倒排索引
- 正排索引:通过key寻找value
- 倒排索引:通过value寻找key。全文检索中value找到对应的文档
4.2 路由算法
- 默认路由:shard=hash(routing)%number_of_primary_shards,这里路由策略扩展受到shards个数的限制,扩容的时候需要成倍扩容(es6.x),并且在创建index的时候需要指定未来允许扩容的规模。es5.x不持支扩容,es7.x可以自由扩容
- 自定义路由:存储文档时指定routing值,查询文档时,也需要给出routing的值,该路由方式,通过routing的方式,可以影响文档写入到哪个shard,也可以仅仅检索特定的shard
4.3 平衡算法
- es提供了分片自动平衡功能,使分片均匀分布在es集群中,提高es的负载能力
- 使用场景:扩容、减容、导入数据场景
- 算法如下:
- weight_index(node,index)=indexBalance*(node.numShards(index)-avgShardsNode(index))
- weight_node(node,index)=shardBalance*(node.numShards()-avgShardsNode())
- weight(node,index)=weight_index(node,index)+weight_node(node,index)
node.numShards() 该节点目前总共的分片数
node.numShards(index) 该索引在该节点下的分片数
avgShardsPreNode() 理想状态下,平均每个节点应该分配的分片数
avgShardsPreNode(index) 理想状态下,该索引平均分配到每个节点上的分片数
weight_index默认值0.45
weight_node默认值0.55
weight默认值1
4.4 es扩容
- 扩容场景
- 物理资源消耗过大,即es的服务节点的CPU,内存占用率过高,磁盘存储空间不足
- es单示例索引数据太大,索引的数目达到10亿条或1TB
- 扩容方式
- 增加node实例
- 增加节点,在新节点部署新的node实例
- 扩容后,采用自动均衡策略进行分片的自动平衡
4.5 es减容
- 减容场景
- 减容方式
- 减容注意事项
- 确保要删除的实例上的shard下的replica在其他实例存在
- 确保要删除的实例上的数据已经迁移到其他节点
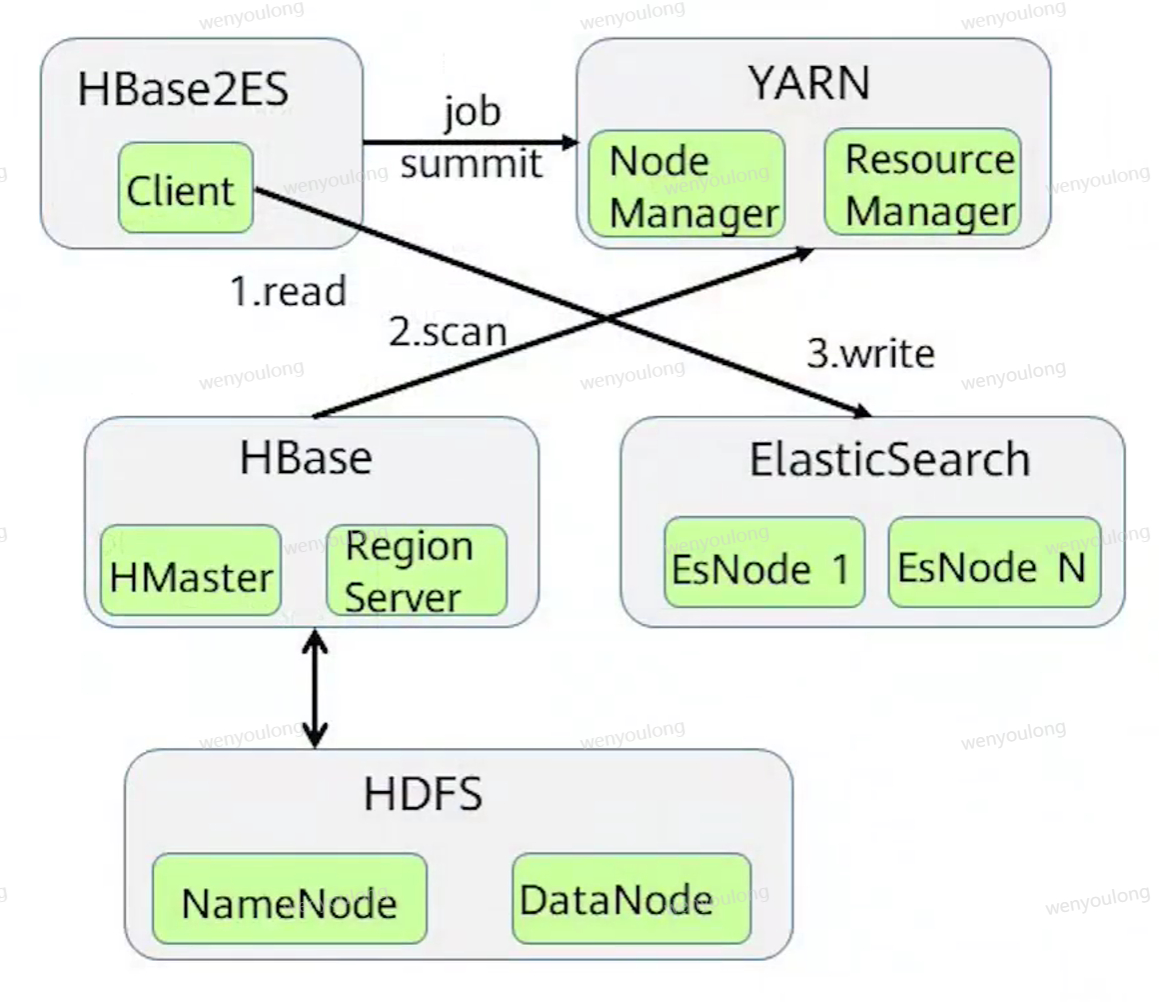
4.5 es索引HBase数据
- 在HBase数据写入的同时,在es建立相应的HBase索引数据,其中索引ID与HBase数据的rowkey对应,保证每条索引数据与HBase数据的唯一,实现HBase数据的全文索引
- 批量索引:针对HBase中已有的数据,通过提交MR任务的形式,将HBase中的全部数据读出,然后在es中建立索引
4.7 es单节点多实例部署
在同一个节点上部署多个es实例,根据IP和不同的端口号来区分不同的es实例,可以提高单节点的CPU、磁盘和内存利用率,提高es的索引和搜索能力
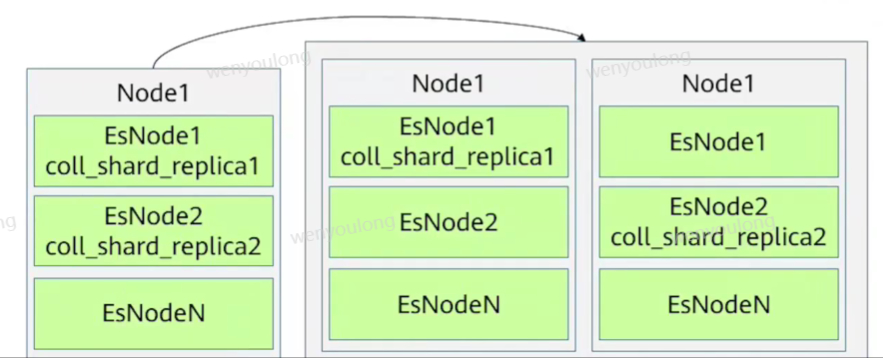
4.8 es副本自动跨节点分配策略
单节点多实例部署下,多副本时,如果只做到跨实例分配,存在单点故障,增加默认配置cluster.routing.allocation.same_shard.host:true即可。
4.8 es新特性
- HBase全文索引特性,
- 通过建立HBase和es索引的映射关系,支持索引存储es,而原始数据存储HBase
- 加密鉴权特性
参考
【腾讯云ES】分片均衡算法深入浅出-腾讯云开发者社区-腾讯云 (tencent.com)
ElasticSearch分布式全文检索_在线课程_华为云开发者学堂_云计算培训-华为云 (huaweicloud.com)
 wenyl 的个人博客
wenyl 的个人博客