
去github中下载自己的elasticsearch对应版本的分词器插件,我的elasticsearch版本为7.4.2,所以我下载的IK分词器插件版本也是7.4.2
Releases · medcl/elasticsearch-analysis-ik (github.com)
使用docker创建elasticsearch时,我们关联了一个plugins目录,将解压后的目录移动到该文件夹下
如果是下载包进行的安装,也可以在elasticsearch目录下找到plugins文件夹
然后重启elasticsearch即可
重启后,查看elasticsearch日志提示已经加载了IK分词器
IK分词器支持最细粒度分词(ik_max_word)和最粗粒度分词(ik_smart)
最细粒度分词会将输入的文本,根据词典进行最细粒度的拆分,一段文本可能会分出很多词,如下示例
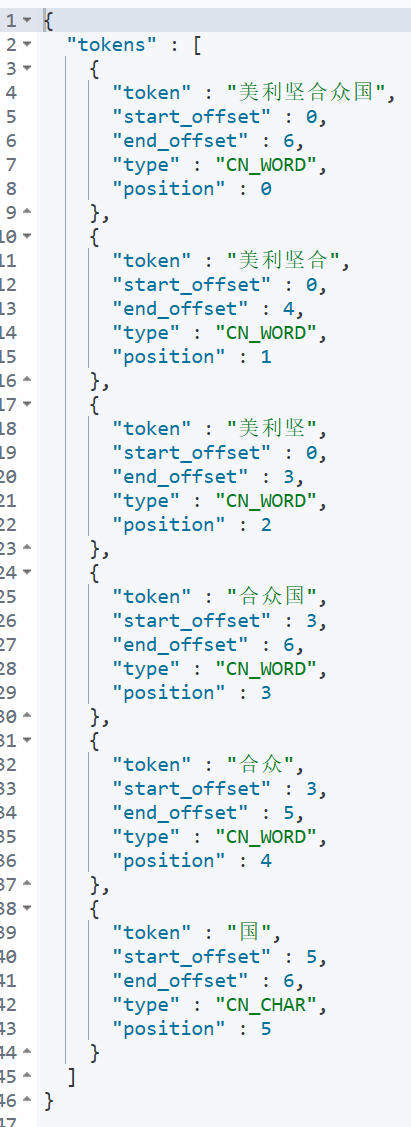
在kibana中使用最细粒度分词对美利坚合众国进行分词
GET _analyze
{
"analyzer": "ik_max_word",
"text": "美利坚合众国"
}
得到结果如下
使用最粗粒度分词对美利坚合众国进行分词
GET _analyze
{
"analyzer": "ik_smart",
"text": "美利坚合众国"
}
得到结果如下

在下载的IK-Analysis插件中,config目录下有一个IKAnalyzer.cfg.xml文件,该文件内容如下
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
此时,我们需要添加自定义的词典,my.dic如下所示
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
然后再config目录下新建my.dic文件,并再里面添加龙龙龙
然后重启elasticsearch
再kibana中执行下述命令
GET _analyze
{
"analyzer": "ik_smart",
"text": "你好龙龙龙"
}
分词结果如下,龙龙龙,被作为一个词语进行了分词

在es的配置文件elasticsearch.yml中新增配置,重启elasticsearch
# 缓存回收大小,无默认值
# 有了这个设置,最久未使用(LRU)的 fielddata 会被回收为新数据腾出空间
# 控制fielddata允许内存大小,达到HEAP 20% 自动清理旧cache
indices.fielddata.cache.size: 20%
indices.breaker.total.use_real_memory: false
# fielddata 断路器默认设置堆的 60% 作为 fielddata 大小的上限。
indices.breaker.fielddata.limit: 40%
# request 断路器估算需要完成其他请求部分的结构大小,例如创建一个聚合桶,默认限制是堆内存的 40%。
indices.breaker.request.limit: 40%
# total 揉合 request 和 fielddata 断路器保证两者组合起来不会使用超过堆内存的 70%(默认值)。
indices.breaker.total.limit: 95%
 wenyl 的个人博客
wenyl 的个人博客