
jupyter中新建一个notebook
print('hello world!')
运行结果如下
Python使用缩进划分代码块而不是{}
PEP8规范是Python代码在书写时遵守的规范,并不是语法规则
已经定义好的具有一些特殊功能的关键字,查看关键字命令 help("keywords")
输出结果如下
标识符由数字、字母和下划线组成,且不能用数字作为开头,不能和关键字重名
# 文件名:test.py
'''
这是多行注释,使用单引号。
这是多行注释,使用单引号。
这是多行注释,使用单引号。
'''
"""
这是多行注释,使用双引号。
这是多行注释,使用双引号。
这是多行注释,使用双引号。
"""
一行中使用多个语句;分割
print("hello");print("world");
一个语句分成多行可以用/分割
total = 0
a = 1
b = 2
c = 1
total = a + \
b + \
c
print(total)
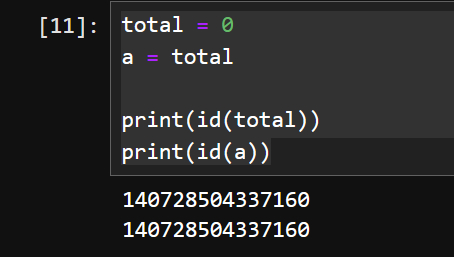
变量是对数据存储地址的引用,给变量赋值并不是将数据赋予变量,而是将数据所在的存储地址赋给变量
使用id()可以查看对象的内存地址
作用域就是程序运行时变量可被访问的范围
定义在函数和对象外部,作用范围是整个模块
定义在函数内的变量,作用范围只能是在函数内
使用import 和 from ... import ...进行包和模块的导入
| 函数 | 功能 |
|---|---|
| 输出 | |
| input | 输入 |
| range(start,stop,[step]) | 生成可迭代序列(起始位置,中止位置,步长) start省略默认值为0,stop不能省略且要大于0,step省略默认值为1 |
| type | 返回对象的类型 |
| del | 在内存中删除对象 |
| dir | 查看对象的内置方法和属性 |
| help | 显示对象的帮助信息 |
| id | 查看对象内存地址 |
代码示例如下
#print函数
print("print()函数")
# input函数
a = input("input:")
print(a)
#range函数
temp = range(0,5,1)
print(list(temp))
#type函数
print(type(temp))
#dir函数
import math
print("模块 math 的属性和方法:", dir(math))
# help函数
print(help(math))
# id函数
print(id(temp))
#del函数
del(temp)
if语句语法如下
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
condition可以是一个结果为True或者False的表达式,也可以是数字,如果是数字则有非0为真的逻辑
a = int(input("输入a="))
if a==1:
print("输入1")
elif a == 2:
print("输入2")
else:
print("输入其他值")
语法如下:
match subject:
case <pattern_1>:
<action_1>
case <pattern_2>:
<action_2>
case <pattern_3>:
<action_3>
case _:
<action_wildcard>
match 后的对象会依次与 case 后的内容进行匹配,如果匹配成功,则执行匹配到的表达式,否则直接跳过,_ 可以匹配一切
http_status = int(input("输入http状态码="))
match http_status:
case 400:
print('参数异常')
case 404:
print('资源不存在')
case 500:
print('服务错误')
case _:
print("其他错误")
for 循环可以遍历任何可迭代对象,else用于在循环结束后执行一段代码可以省略不写
for语句语法
for <variable> in <sequence>:
<statements>
else:
<statements>
遍历一个列表如下:
list = [1,2,3,4,5]
for item in list:
print(item)
else:
print("循环结束")
Python没有do...while循环
while <expr>:
<statement(s)>
else:
<additional_statement(s)>
使用while来移除一个列表中的数据
list = [1,2,3,4,5,6,7,8,9,10]
while len(list) > 0:
print(list.pop())
else:
print("循环结束")
使用break和continue实现循环终止
break结束循环
list = [1,2,3,4,5,6,7,8,9,10]
while len(list) > 0:
print(list.pop())
if len(list) == 5:
break
else:
print("循环结束")
continue跳过本轮循环
list = [1,2,3,4,5]
for item in list:
if item == 5:
continue
else:
print(item)
函数的优点:
函数声明语法如下,在函数体中可以使用return返回一个值
def 函数名(参数列表):
函数体
函数示例如下,定于一个求和函数
def sumFunc(a,b):
return a+b
函数的参数有以下几种情况
必备参数必须以正确的顺序传如函数,调用时的数量必须和声明是的一样
def sumFunc(a,b):
return a+b
参数调用时使用等号调用的形式传入参数,使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值
def sumFunc(a,b):
print(a)
print(b)
return a+b
print(sumFunc(b=1,a=2))
调用函数时,缺省参数的值如果没有传入则使用默认值
def sumFunc(a=0,b=0):
print(a)
print(b)
return a+b
print(sumFunc())
可能需要一个函数能处理比当初声明时更多的参数,这些参数叫做不定长参数,声明时不会命名,加了星号 的参数会以元组(tuple)的形式导入,加了两个星号的参数会以字典的形式导入。
参数以元组形式传入如下:
def sumFunc(a,*tuple):
print(a)
print(tuple)
sumFunc(1,2,3,4)
参数以字典形式传入如下:
def countAge(age,**dict):
print(age)
print(dict)
countAge(1,a=2,b=3)
参数顺序排列为:
必备参数、关键字参数、默认参数、不定长参数
函数体中没有return,函数返回None值
函数体有return,并返回了一个值
函数体有return,且返回多个值,这些值会封装成一个元组返回
传递的参数有两种类型
不可变类型实例:
def unChange(a):
print(id(a))
a = 10
print(id(a))
arg = 1
unChange(arg)
print(arg)
可变类型实例:
def unChange(a):
print(id(a))
a = 10
print(id(a))
arg = 1
unChange(arg)
print(arg)
python使用lambda关键字创建匿名函数
sum = lambda a,b:a+b
print(sum(1,2))
将匿名函数封装在一个函数内,这样可以使用同样的代码来创建多个匿名函数
def myFunc(n):
return lambda a:a*n
func1 = myFunc(2)
func2 = myFunc(3)
print(func1(11))
print(func2(11))
面向对象三大特性
面向对象的优势:
Python使用class关键字声明一个类
class Animal:
name = "动物"
def sayName(self):
print("名称=%s" % self.name)
a = Animal()
print(a.name)
a.sayName()
Python默认构造函数是 __init__()
class Animal:
name = ""
def __init__(self,nameArg):
self.name = nameArg
def sayName(self):
print("名称=%s" % self.name)
a = Animal("动物")
print(a.name)
a.sayName()
self代表类的实例而不是类本身
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
Python在类名后加(父类名)实现一个继承
class Animal:
name = ""
__age = 0 # 私有属性
def __init__(self,nameArg,ageArg):
self.name = nameArg
self.age = ageArg
def sayName(self):
print("名称=%s,年龄%d" % (self.name,self.age))
# 子类
class Cat(Animal):
color = ""
def __init__(self,colorArg,nameArg,ageArg):
Animal.__init__(self,nameArg,ageArg)
self.color = colorArg
def sayName(self):
print("名称=%s,年龄%d,颜色%s" % (self.name,self.age,self.color))
c = Cat('red',"猫猫",18)
c.sayName()
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
语法如下:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
#!/usr/bin/python3
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
#另一个类,多继承之前的准备
class speaker():
topic = ''
name = ''
def __init__(self,n,t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一个演说家,我演讲的主题是 %s"%(self.name,self.topic))
#多继承
class sample(speaker,student):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
test = sample("Tim",25,80,4,"Python")
test.speak() #方法名同,默认调用的是在括号中参数位置排前父类的方法
可以在子类重写你父类的方法
class Animal:
def sayName(self):
print("Animal的sayName方法" )
class Cat(Animal):
def sayName(self):
print("Cat的sayName方法" )
c = Cat()
c.sayName()
#调用被覆盖的父类方法
super(Cat,c).sayName()
python可以将属性和方法私有化
Python使用双下划线修饰属性或方法表示设个属性或方法为私有,不能再类的外部使用或直接访问,在内部使用self关键字访问
可以利用专有方法实现运算符重载,实例如下
#!/usr/bin/python3
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print (v1 + v2)
Python标准库主要有以下三个
Python第三方库主要有以下三个:
Python打开文件的函数为 f = open(filePath,mode,encoding)
文件打开模式有以下几种:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
| 函数 | 作用 |
|---|---|
| read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有 |
| readline([size]) | 读取整行,包括 "\n" 字符。 |
| readlines([sizeint]) | 读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 |
| 函数 | 作用 |
|---|---|
| write(str) | 将字符串写入文件 |
| writelines(sequence) | 将序列字符串列表写入文件 |
| 函数 | 作用 |
|---|---|
| close() | 关闭文件。关闭后文件不能再进行读写操作。 |
| flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入 |
 wenyl 的个人博客
wenyl 的个人博客