
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配
re 模块使 Python 语言拥有全部的正则表达式功能
正则表达式可以实现文本的匹配、替换和搜索,常用于服务器日志文件的信息检索和匹配、爬虫数据获取等
| 函数 | 作用 |
|---|---|
| compile(pattern,flag=0) | 获取一个正则对象 |
| match(pattern,string,flag=0) | 从字符串头开始匹配 |
| search(pattern,string,flag=0) | 匹配整个字符串,直到找到一个匹配 |
| findall(pattern,string,flag=0) | 查找字符串中所有出现的正则表达式模式,返回列表 |
| split(pattern,string,max=0) | 根据正则表达式把字符串拆分为列表,max为最多分割次数 |
| sub(pattern,repl,string,count=0) | 使用repl替换正则表达式出现在string中的位置 |
import re
# 得到一个正则对象
res = re.compile("a")
print( res.search("abcd").group())
# 从头匹配一个abcd字符串
print(re.match("abcd","abcd abcd").group())# 在起始位置返回abcd
print(re.match("abcd","abc abcd"))# abcd不在起始位置返回None
# 扫描整个字符串并返回第一个成功的匹配
print(re.search("abcd","abcd abcd").group())# 在起始位置返回abcd
print(re.search("abcd","abc abcd").group())# abcd不在起始位置返回abcd
# 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表
print(re.findall("abcd","abcd abcd"))
print(re.findall("abcd","abc abcd"))
pattern = re.compile("abcd")
print(pattern.findall("abcd abcd",0,3))# 通过pattern.findall可以指定字符串搜索起始位置和结束位置
# split 方法按照能够匹配的子串将字符串分割后返回列表
print(re.split("ab","abcd abgh"))
print(re.split("ab","abcd abgh",1))# 可以指定最大拆分次数
#替换字符串中的匹配项
print(re.sub("ab","替换","abcd abgh"))
print(re.sub("ab","替换","abcd abgh",1)) # 设置最大替换次数
| 函数 | 作用 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组 |
| groups(default=None) | 返回一个包含所有小组字符串的元组 |
| groupdict(default=None) | 返回一个包含所有小组字符串的元组 |
| re.i或re.IGNORECASE | 匹配忽略大小写 |
| re.M或re.MULTILINE | 多行匹配,影响**^** 和**$**,使它们匹配字符串的每一行的开头和结尾 |
group案例
import re
text = "123abc456"
pattern = re.compile('(\d+)(\w+)(?P<name>\d+)')
match = pattern.match(text)
if match:
print(match.group(0)) # 输出整个正则表达式的匹配结果
print(match.group(1)) # 输出第一个括号里匹配的结果
print(match.group(2)) # 输出第二个括号里匹配的结果
print(match.group('name')) # 输出名为'name'的组匹配的结果
groups案例
import re
text = "123abc456"
pattern = re.compile('(\d+)(\w+)(?P<name>\d+)')
match = pattern.match(text)
if match:
print(match.groups()) # 输出一个包含所有括号里匹配的结果的元组
groupdict案例
import re
text = "123abc456"
pattern = re.compile('(\d+)(\w+)(?P<name>\d+)')
match = pattern.match(text)
if match:
print(match.groupdict()) # 输出一个包含所有命名组匹配结果的字典
忽略大小写案例
import re
pattern = re.compile(r'apple', flags=re.IGNORECASE)
result = pattern.match('Apple')
print(result.group()) # 输出: 'Apple'
处理多行文本案例
import re
print(re.findall(r'^\d+','123\n456\n789')) # 不加多行处理只匹配第一行
print(re.findall(r'^\d+','123\n456\n789',re.M)) # 匹配多行
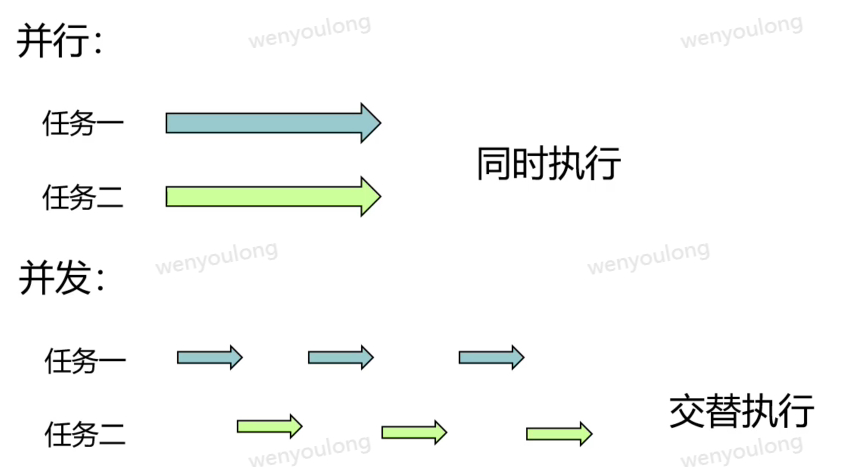
python有两种创建线程的方法
调用 _thread 模块中的start_new_thread()函数来产生新线程
语法为 _thread.start_new_thread ( function, args[, kwargs] )
import _thread
def print_num(threadName):
count = 0
while count <5:
print("%s-%d" % (threadName,count))
count += 1
_thread.start_new_thread(print_num,("线程1",))
_thread.start_new_thread(print_num,("线程2",))
我们可以通过直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程,即它调用了线程的 run() 方法
import threading
class MyThread(threading.Thread):
def __init__(self,threadName):
# 调用父类构造函数
threading.Thread.__init__(self)
self.threadName = threadName
def run(self):
count = 0
while count <100:
print("%s-%d" % (self.threadName,count))
count += 1
thread1 = MyThread("线程1")
thread2 = MyThread("线程2")
thread1.start()
thread2.start()
threading.Thread 类在 Python 的 threading 模块中提供了创建和管理线程的功能。下面列出了一些常用的 threading.Thread 方法和属性:
方法:
__init__(self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None)group: 线程组,通常不使用。target: 要由线程执行的函数。name: 线程名。args: 传递给 target 函数的参数元组。kwargs: 传递给 target 函数的关键字参数字典。daemon: 指定线程是否是守护线程(默认为 False)。start(self)run(self)Thread 对象时传递 target 函数。join(self, timeout=None)timeout 参数指定了一个非零值,则 join 最多阻塞 timeout 秒。timeout 秒内没有完成,则该方法返回 False;否则返回 True。is_alive(self)True;否则返回 False。set_daemon(self, daemonic)属性:
nameidentdaemon在Python中,线程同步是确保多个线程在访问共享资源时不会发生冲突或数据不一致的技术。Python提供了几种机制来实现线程同步,包括锁(Locks)、条件变量(Condition)、信号量(Semaphores)和事件(Events)。
threading.Lock 是最基本的线程同步机制。当一个线程获得锁时,其他线程必须等待直到该线程释放锁。这确保了同一时间只有一个线程可以访问被保护的代码段。
import threading
import time
import random
# 这是一个共享的资源,即生产者和消费者都会访问的列表
shared_list = []
# 创建一个锁来保护共享资源
lock = threading.Lock()
# 生产者函数
def producer(num_items):
for i in range(num_items):
# 获取锁
lock.acquire()
try:
# 生产一个项目并添加到列表中
item = f"Product {i}"
shared_list.append(item)
print(f"Produced: {item}")
finally:
# 释放锁
lock.release()
time.sleep(random.random()) # 模拟生产时间
# 消费者函数
def consumer(num_items):
for i in range(num_items):
# 获取锁
lock.acquire()
try:
# 从列表中消费一个项目
if not shared_list:
print("No items to consume.")
break
item = shared_list.pop(0)
print(f"Consumed: {item}")
finally:
# 释放锁
lock.release()
time.sleep(random.random()) # 模拟消费时间
# 创建生产者和消费者线程
producer_thread = threading.Thread(target=producer, args=(5,))
consumer_thread = threading.Thread(target=consumer, args=(5,))
# 启动线程
producer_thread.start()
consumer_thread.start()
# 等待线程完成
producer_thread.join()
consumer_thread.join()
print("Production and consumption complete.")
threading.Condition 是一个更高级的同步机制,它允许线程等待某个条件成立。条件变量通常与一个锁一起使用。
import threading
import time
import random
# 定义缓冲区大小
BUFFER_SIZE = 10
# 创建一个共享的队列和条件变量
queue = []
condition = threading.Condition()
# 生产者类
class Producer(threading.Thread):
def run(self):
global queue
while True:
# 获取条件变量的锁
with condition:
# 如果队列已满,生产者等待消费者消费
while len(queue) == BUFFER_SIZE:
print(f"{self.name} (Producer): Queue is full, waiting...")
condition.wait()
# 生产一个随机数作为产品放入队列
item = random.randint(1, 100)
queue.append(item)
print(f"{self.name} (Producer): Produced {item}, current queue size: {len(queue)}")
# 唤醒可能在等待的消费者
condition.notify_all()
# 模拟生产间隔
time.sleep(random.uniform(0.5, 1))
# 消费者类
class Consumer(threading.Thread):
def run(self):
global queue
while True:
# 获取条件变量的锁
with condition:
# 如果队列为空,消费者等待生产者生产
while not queue:
print(f"{self.name} (Consumer): Queue is empty, waiting...")
condition.wait()
# 从队列头部取出一个产品并消费
item = queue.pop(0)
print(f"{self.name} (Consumer): Consumed {item}, current queue size: {len(queue)}")
# 唤醒可能在等待的生产者
condition.notify_all()
# 模拟消费间隔
time.sleep(random.uniform(0.5, 1))
# 创建并启动生产者和消费者线程
producer = Producer(name="Producer")
consumer = Consumer(name="Consumer")
producer.start()
consumer.start()
# 若要让程序持续运行,可添加如下代码
#producer.join()
#consumer.join()
threading.Semaphore 是一个计数器,允许指定同时访问某个资源的线程数量。
import threading
# 创建一个信号量,允许3个线程同时访问资源
semaphore = threading.Semaphore(3)
def resource_access():
with semaphore:
# 被保护的代码段
print("Accessing resource")
# 创建并启动线程
threads = []
for _ in range(5):
t = threading.Thread(target=resource_access)
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
threading.Event 用于在线程之间传递信号。一个线程可以设置一个事件,而其他线程可以等待该事件的发生。
import threading
import time
event = threading.Event()
def waiter():
print("Waiting for the event")
event.wait() # 等待事件发生
print("Event is set!")
def signaler():
time.sleep(2) # 模拟一些工作
event.set() # 设置事件,使等待的线程继续执行
# 创建并启动线程
t1 = threading.Thread(target=waiter)
t2 = threading.Thread(target=signaler)
t1.start()
t2.start()
# 等待所有线程完成
t1.join()
t2.join()
 wenyl 的个人博客
wenyl 的个人博客