
获取到数据后,通过kibana批量添加数据

对指定字段进行分词匹配数据
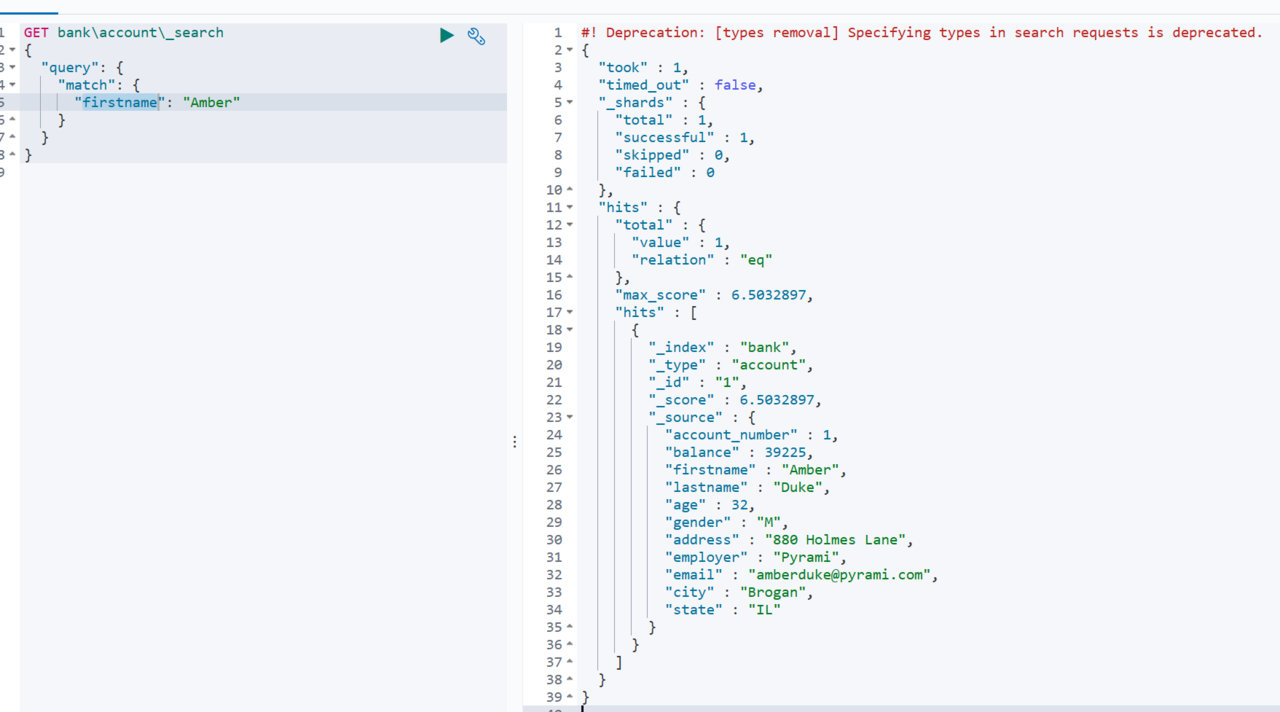
match中,可以通过空格分隔,输入多个词进行匹配,会将符合条件的结果输出
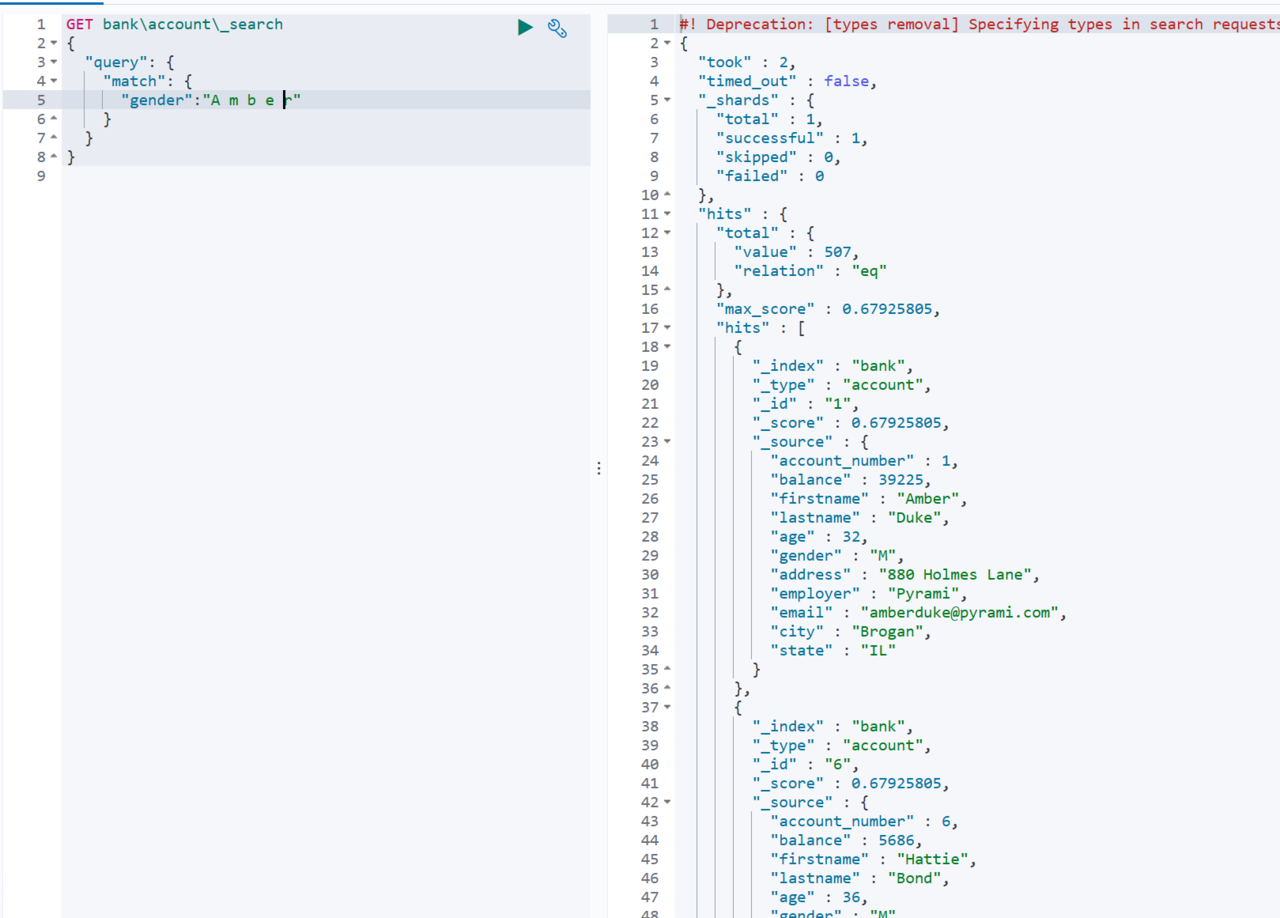
此时如果我们搜索的文本本身就是带着空格的,不希望对他进行分词,则使用match_prase进行匹配
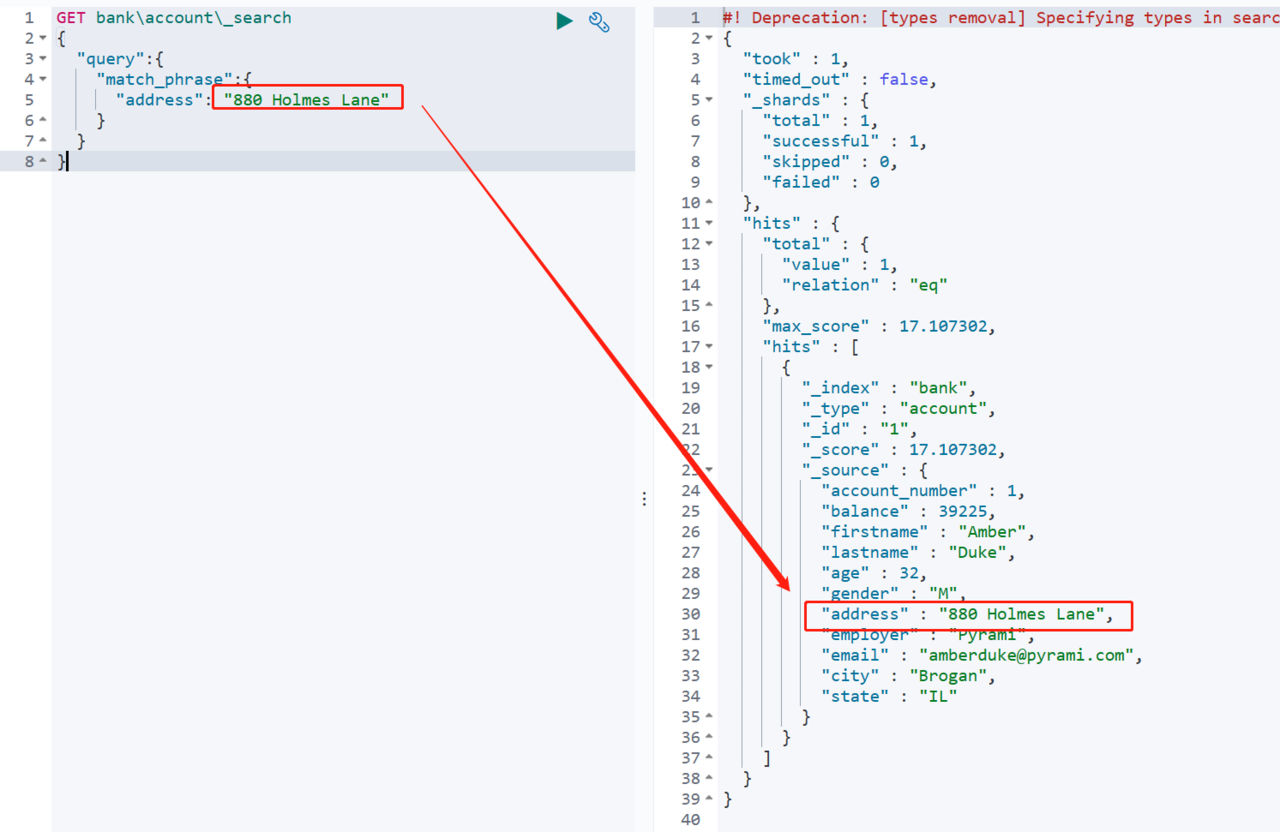
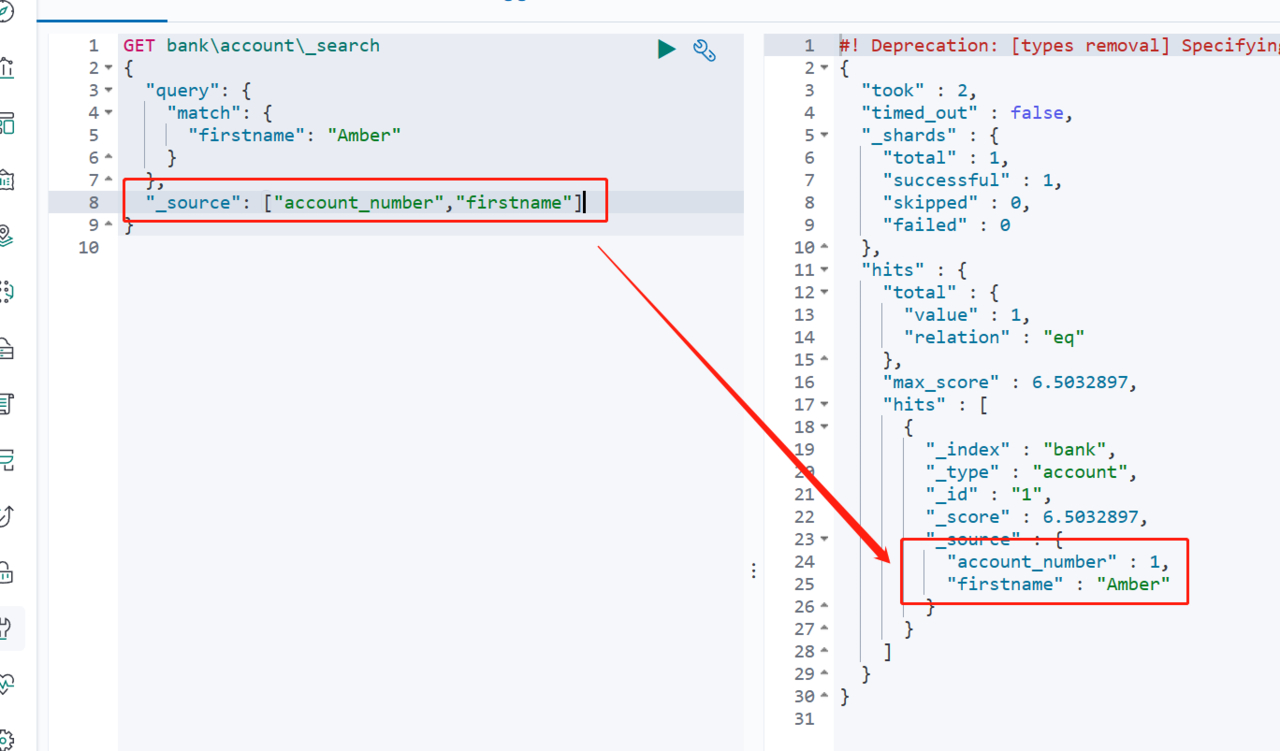
前面使用了match关键字查询数据,发现字段很多,可以通过source关键字,来过滤自己需要的字段
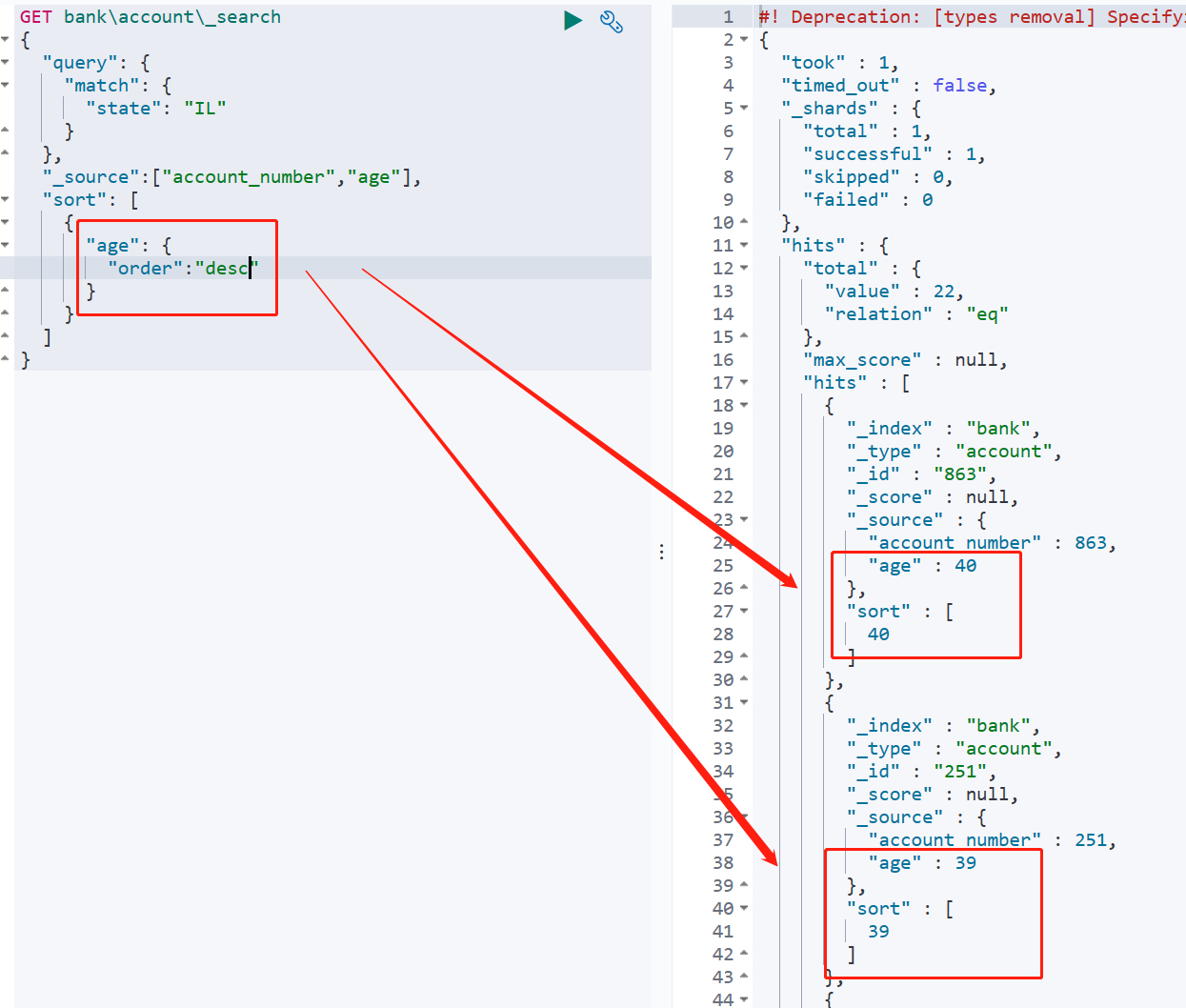
使用sort关键字可以按照指定字段规则进行排序,如下按照年龄降序
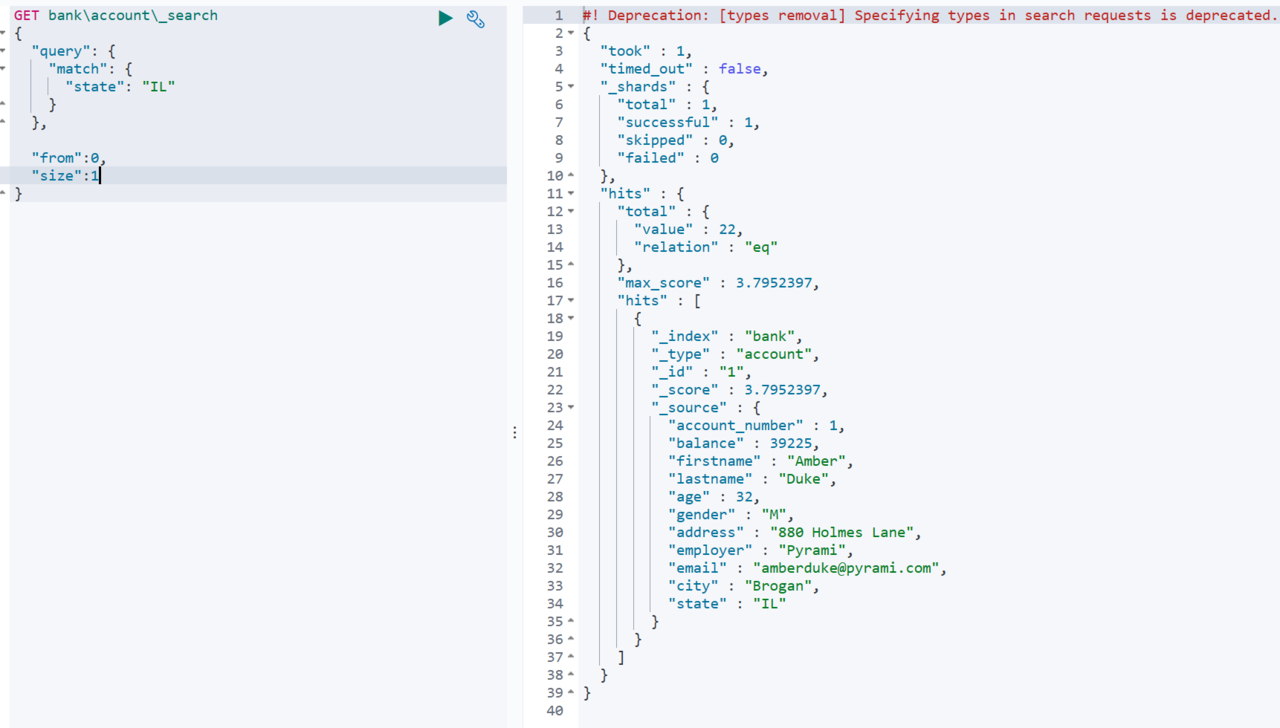
分页查询使用from、size实现,等同于mysql的limit的两个参数
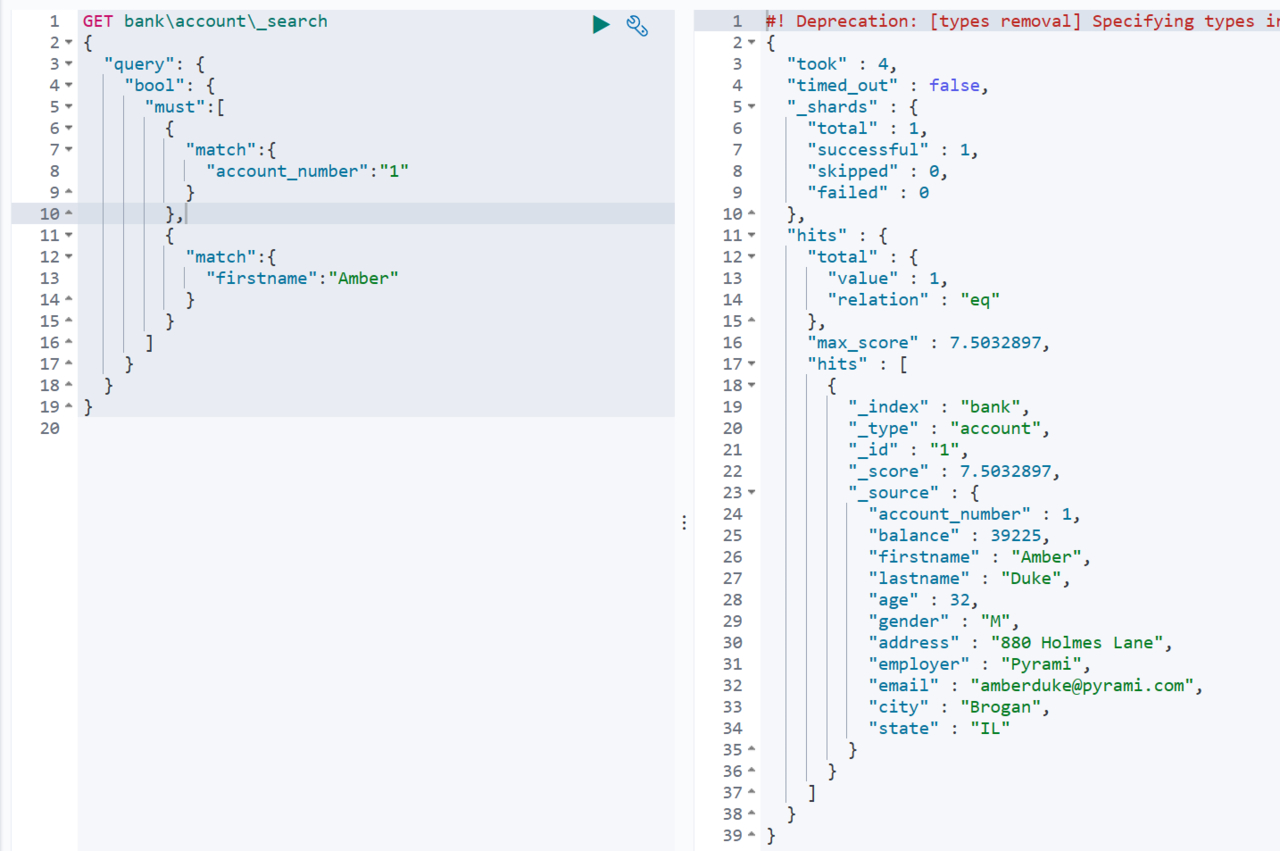
前面我们使用了match来匹配字段,但是如果我们有多个查询字段,则可以通过bool来组合这些查询条件
使用must命令在查询数据时,会查找符合must中定义的所有规则的数据,等同于数据库的and条件
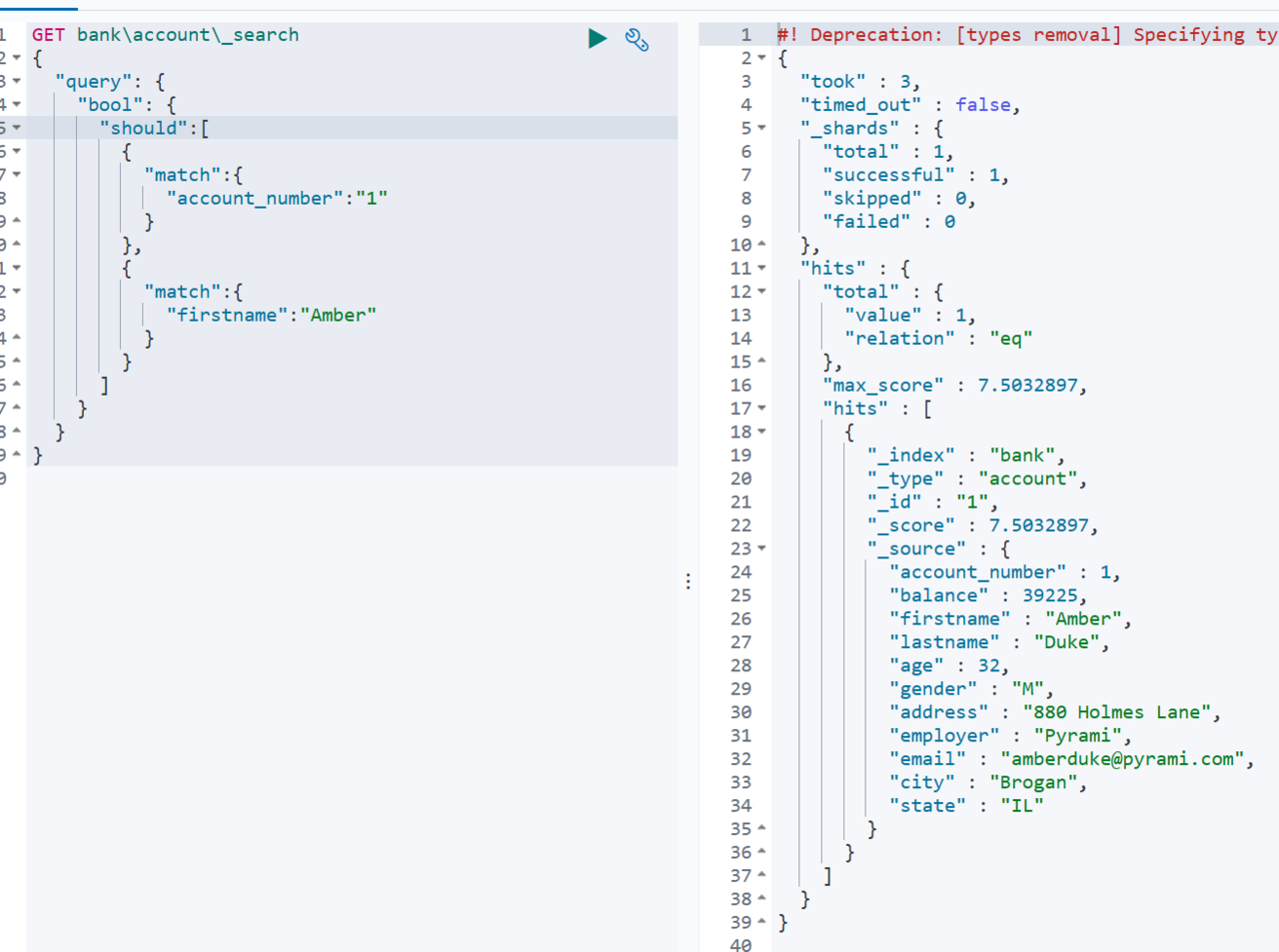
should命令在查询数据时,查询的数据中,只要有任意一个字段符合should中定义的条件就返回,等同于数据库操作中的or
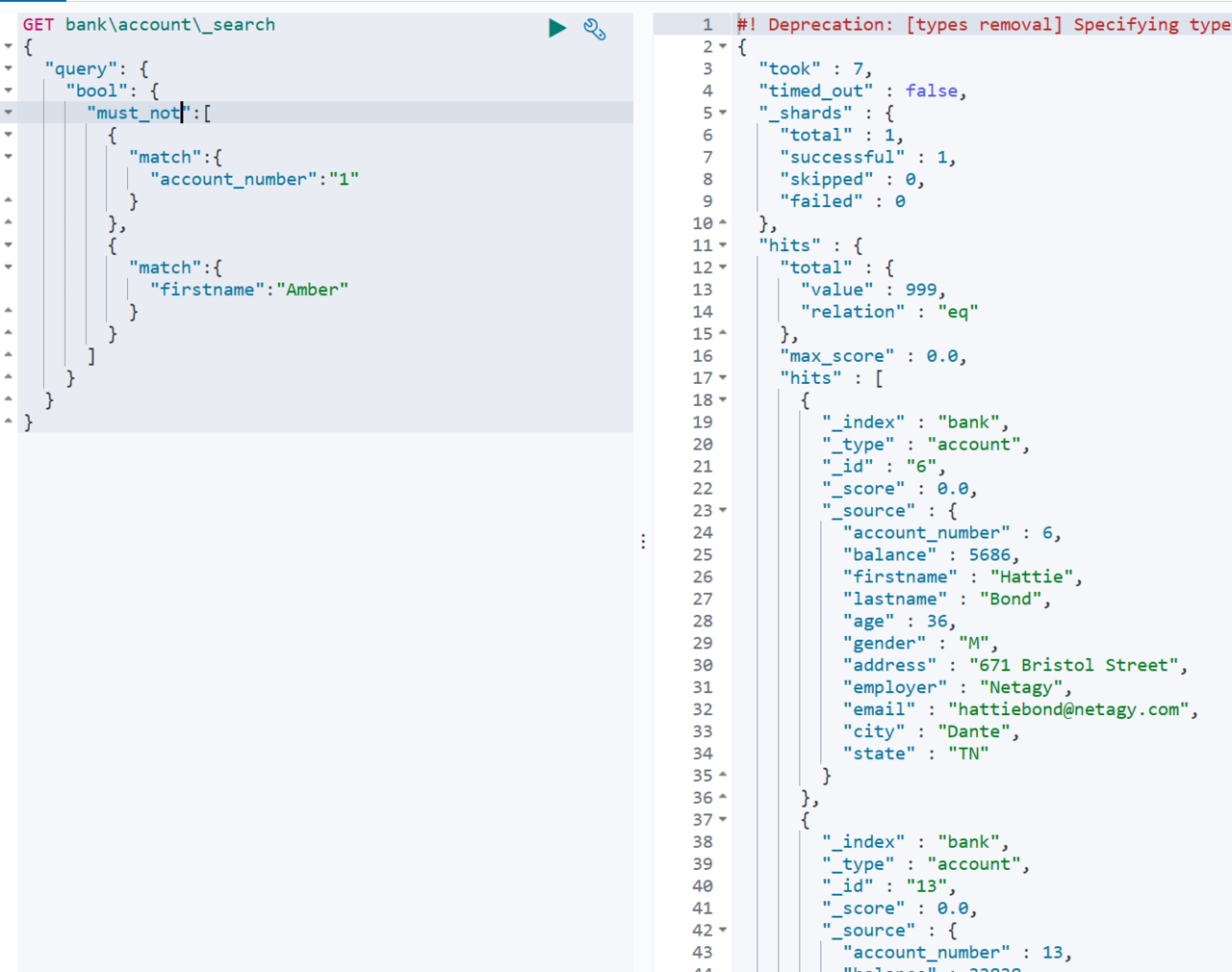
must not可以查询不符合条件的数据,等同于数据库操作中的不等于
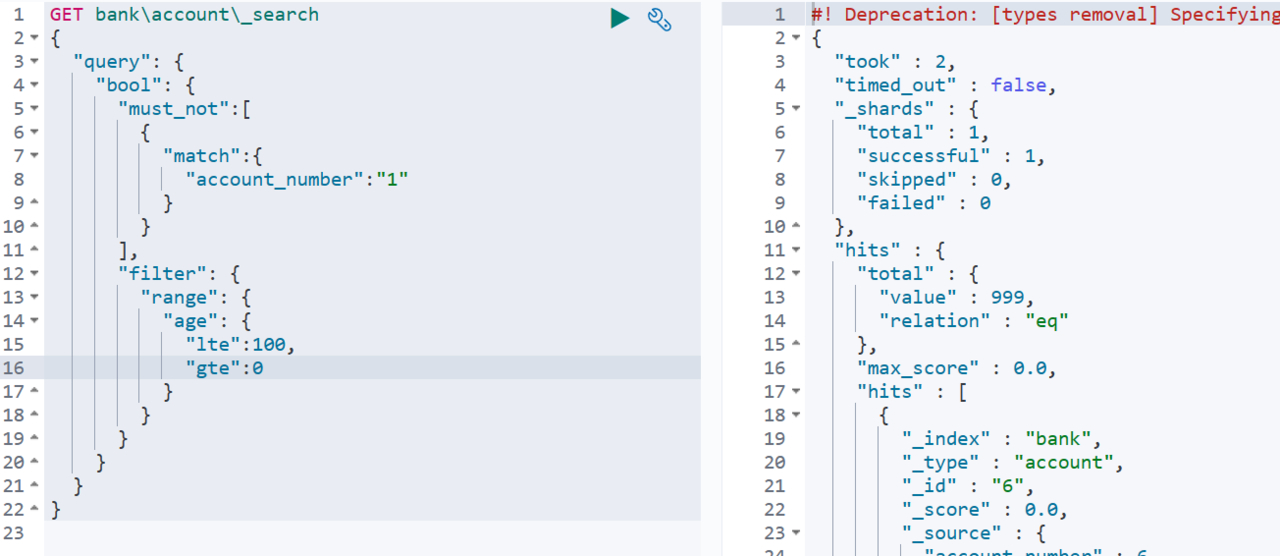
filter可以过滤数据,可以用来根据指定的范围来查询数据
下述代码查询0<=age<=100且账号不等于1的人,
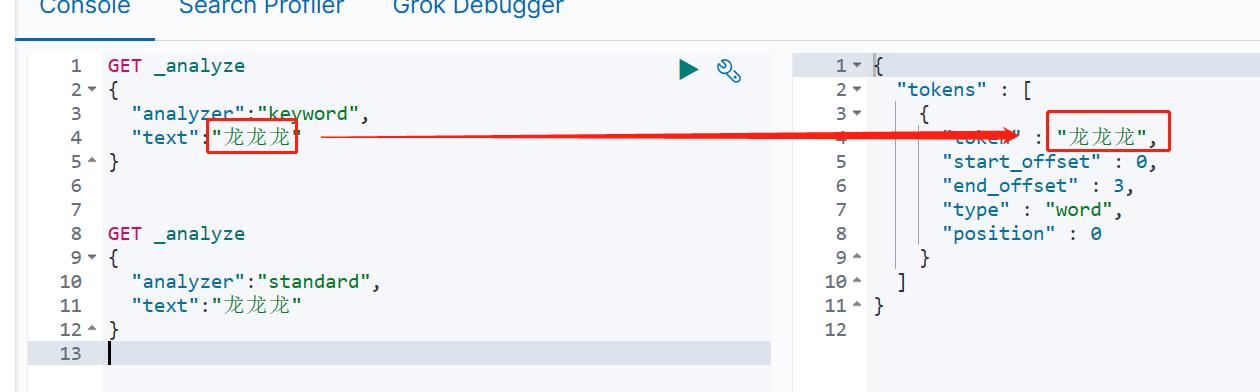
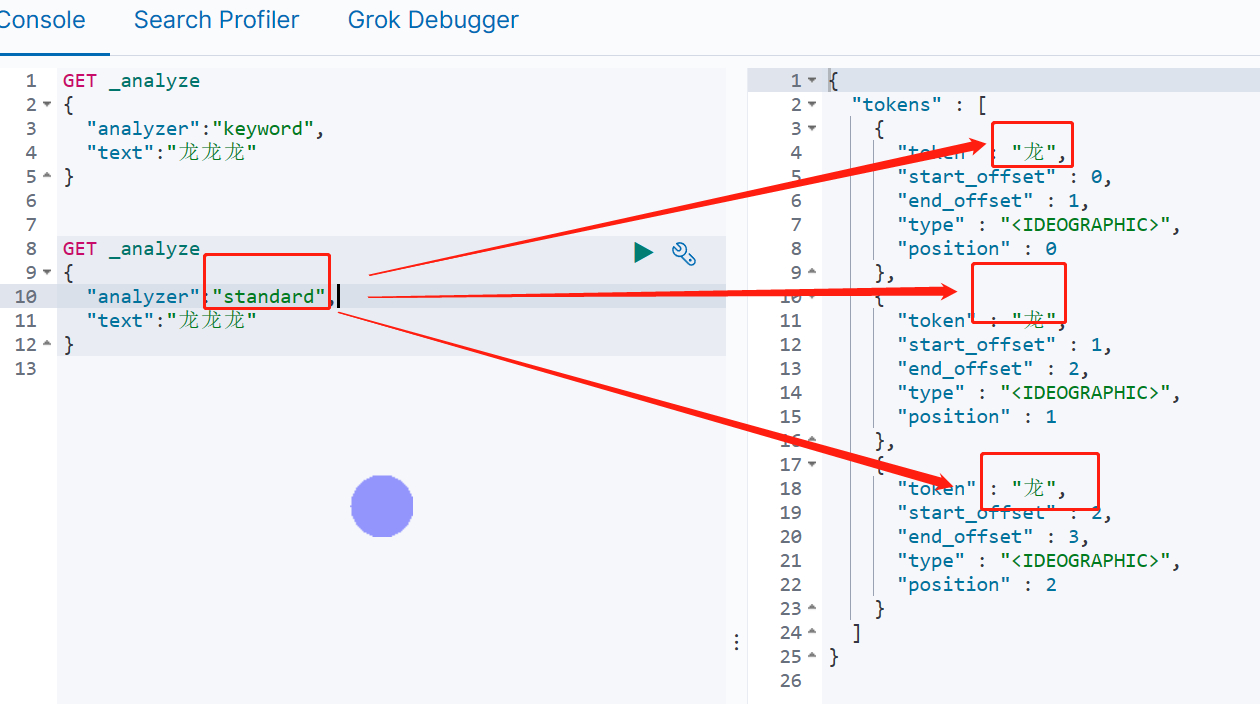
以下面的分词结果为为例,如下所示,指定analyzer为keyword时后,不会被拆分,但是指定analyzer为standard后,对text进行了分词
使用highlight字段可以设置指定字段为高亮
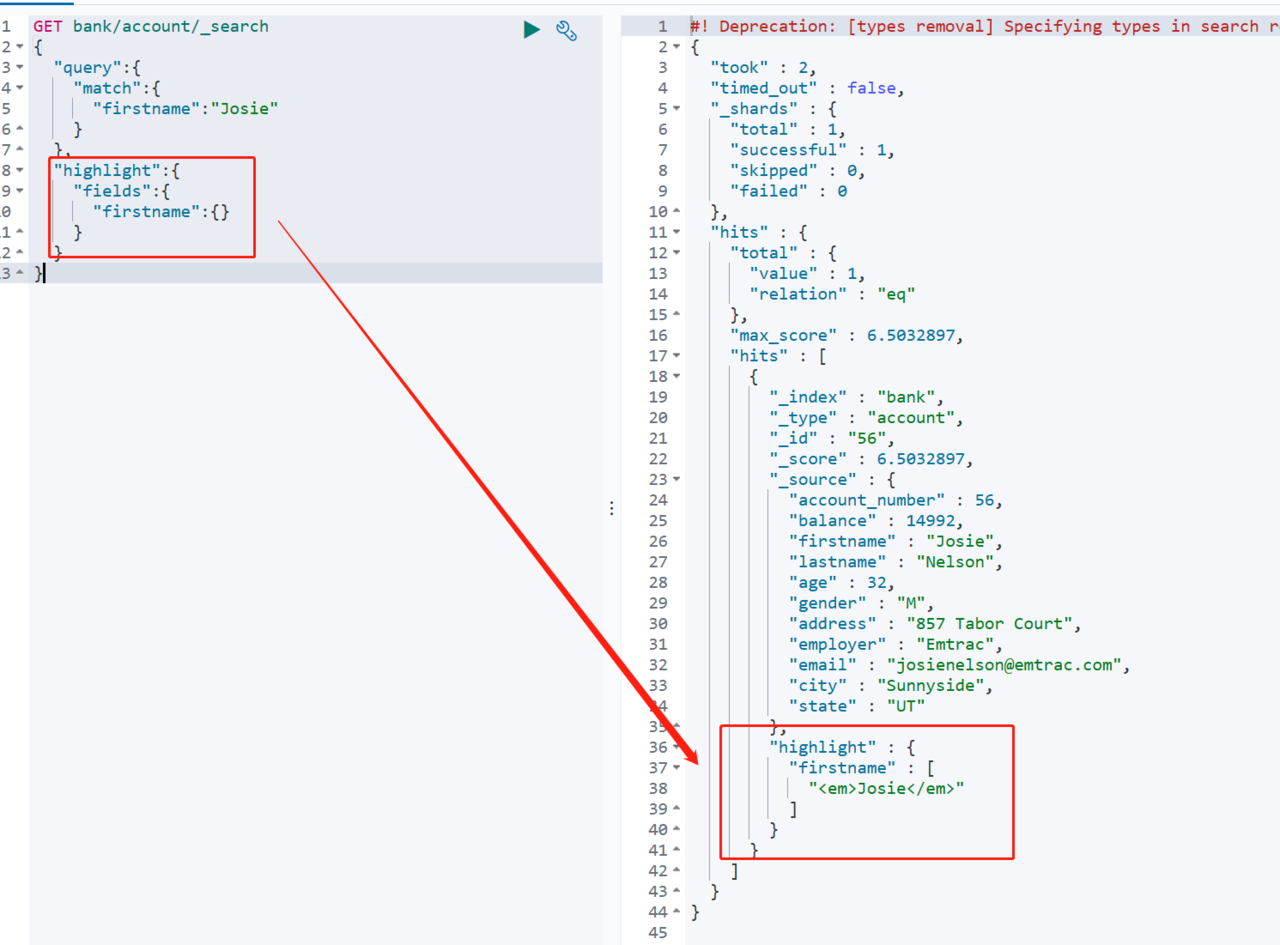
这里我们也可以自定义标签

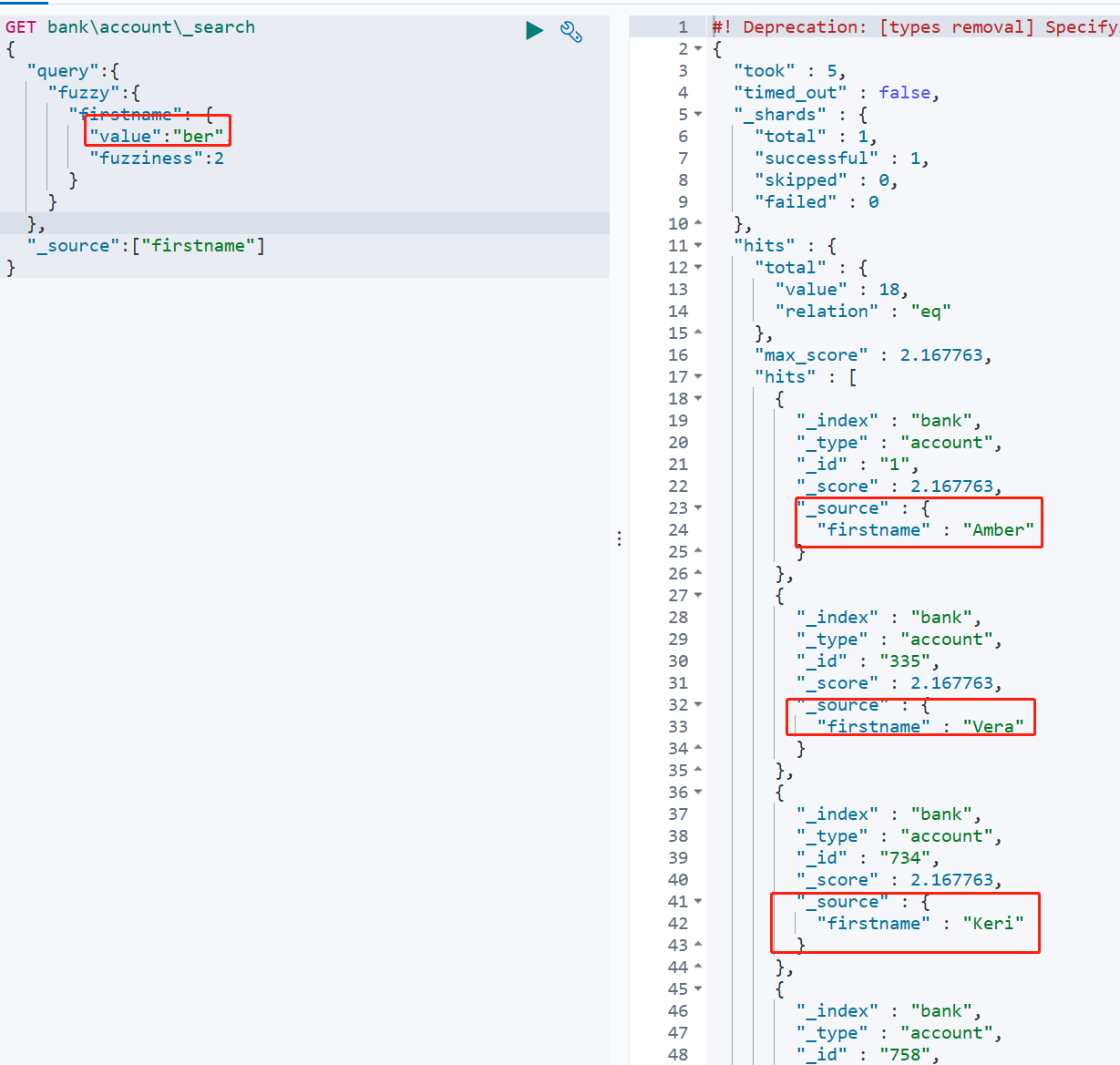
模糊查询可以使用fuzzy来操作,这里的模糊查询与数据库的模糊查询有区别,例如现在有个文本在elasticsearch中存储为hello,然后我输入了一个文本hallo进行匹配,这两个文本时有差异的,但是我可以通过 fuzziness来指定允许的偏差字符数,默认值为2
如下的搜索,搜索的结果与搜索条件的误差字符均不超过2个
 wenyl 的个人博客
wenyl 的个人博客