
聚合就是对分散的数据进行统计、分析、运算,es提供了一些列的聚合操作API,聚合的字段不能被分词
elasticsearch使用桶聚合对文档进行分组,类似SQL中的group by
该示例需要删除注释才能运行
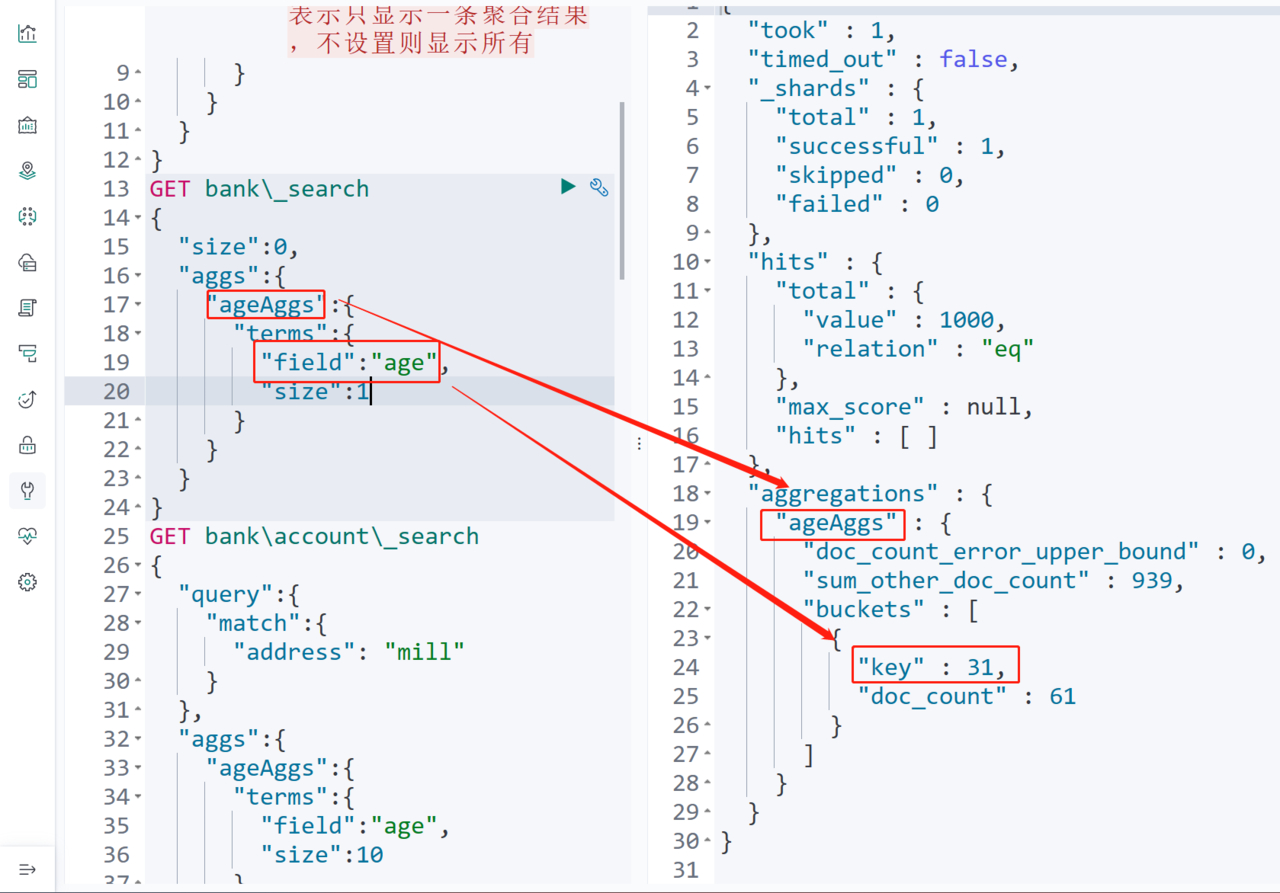
GET bank\_search
{
"size":0, // 文档的数据条数,设置为0表示不显示文档,只显示聚合结果
"aggs":{ // 定义聚合
"ageAggs":{ // 聚合的名称
"terms":{ // 聚合的类型,我们按字段分组所以选择了terms
"field":"age",// 用于分组的字段
"size":1 // 聚合结果的条数,设置为1表示只显示一条聚合结果,不设置则显示所有
}
}
}
}
运行结果如下,这里"age"字段的值就是buckets中的key,doc_count就是每个分组的数量
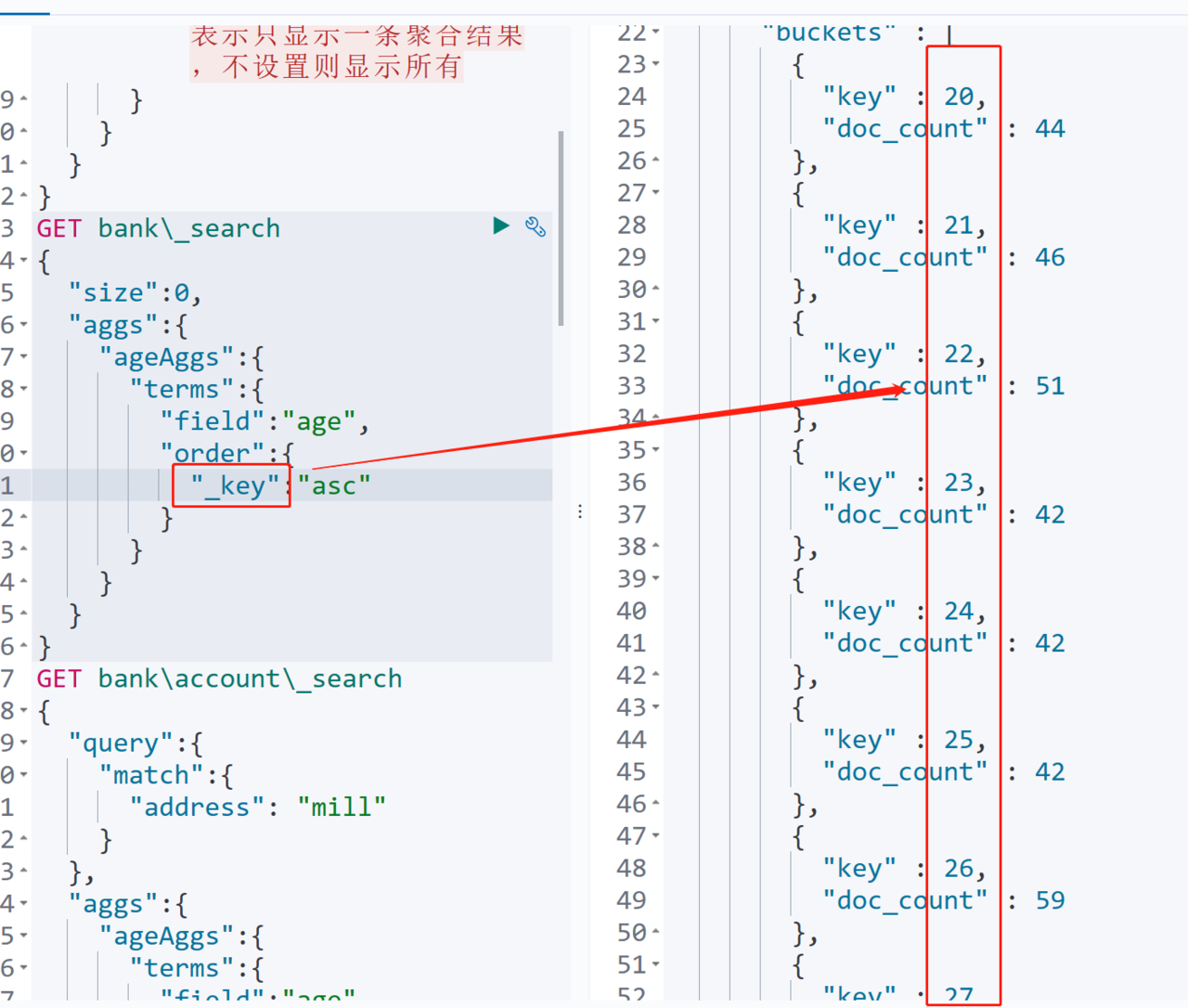
通过order设置排序规则
按照分组关键字进行排序
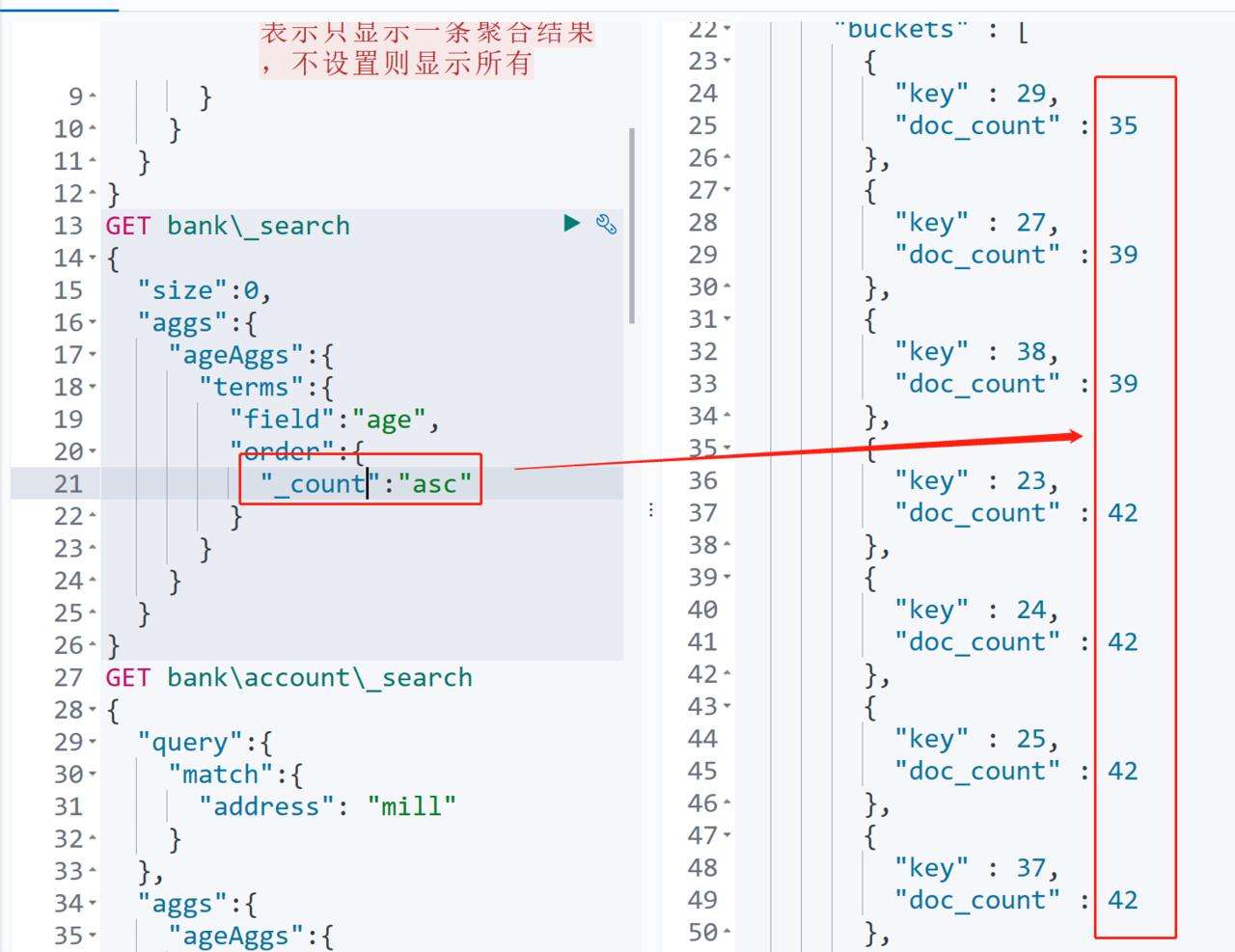
按照分组数量排序
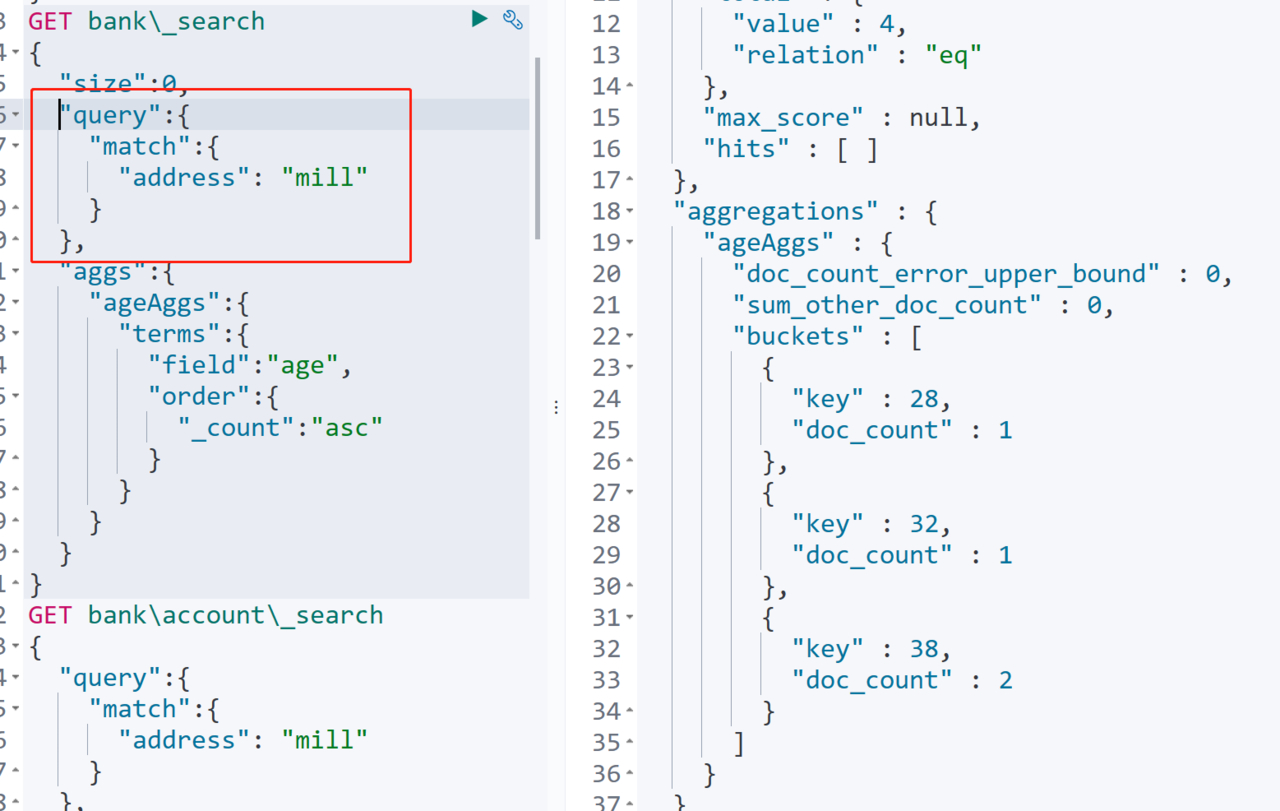
通过添加query条件即可
如下,支队地址包含mill的数据进行聚合操作
elasticsearch通过指标聚合来计算数据的平均值、最小值等信息
GET bank\account\_search
{
"size":0,
"aggs":{ // 聚合操作
"ageStats":{ // 聚合名称
"stats":{ // 聚合类型,stats会自动计算min、max、avg、sum,如果只计算一个,则将stats换成对应的类型即可
"field":"age"// 聚合的字段
}
}
}
}
如下计算了年龄和存款的最大值、最小值、平均值、求和
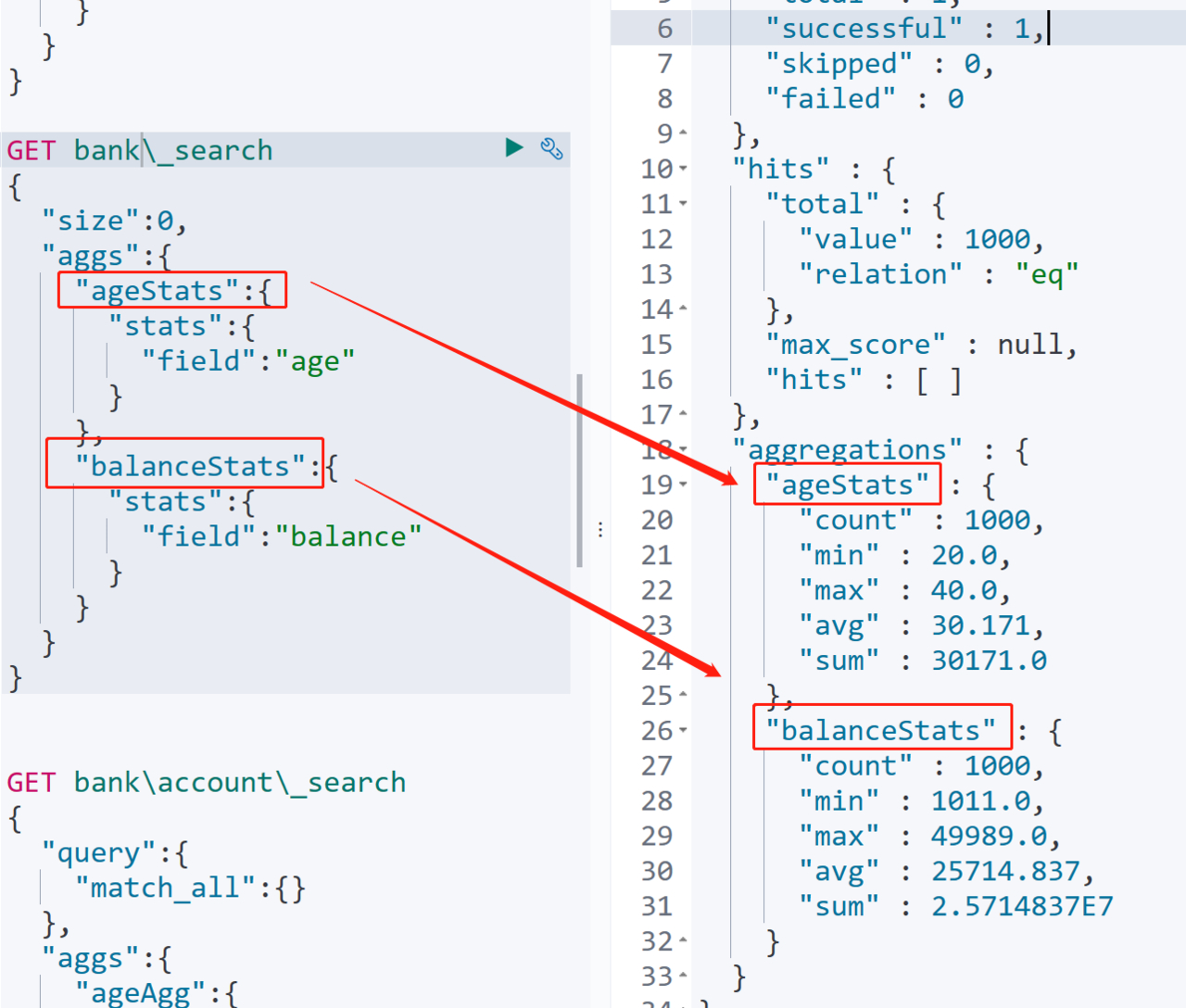
管道聚合其实就是再聚合结果的基础上在做聚合
聚合嵌套的语法规则很简单,再aggs下,可以再添加aggs,不在赘述,可以直接参考示例
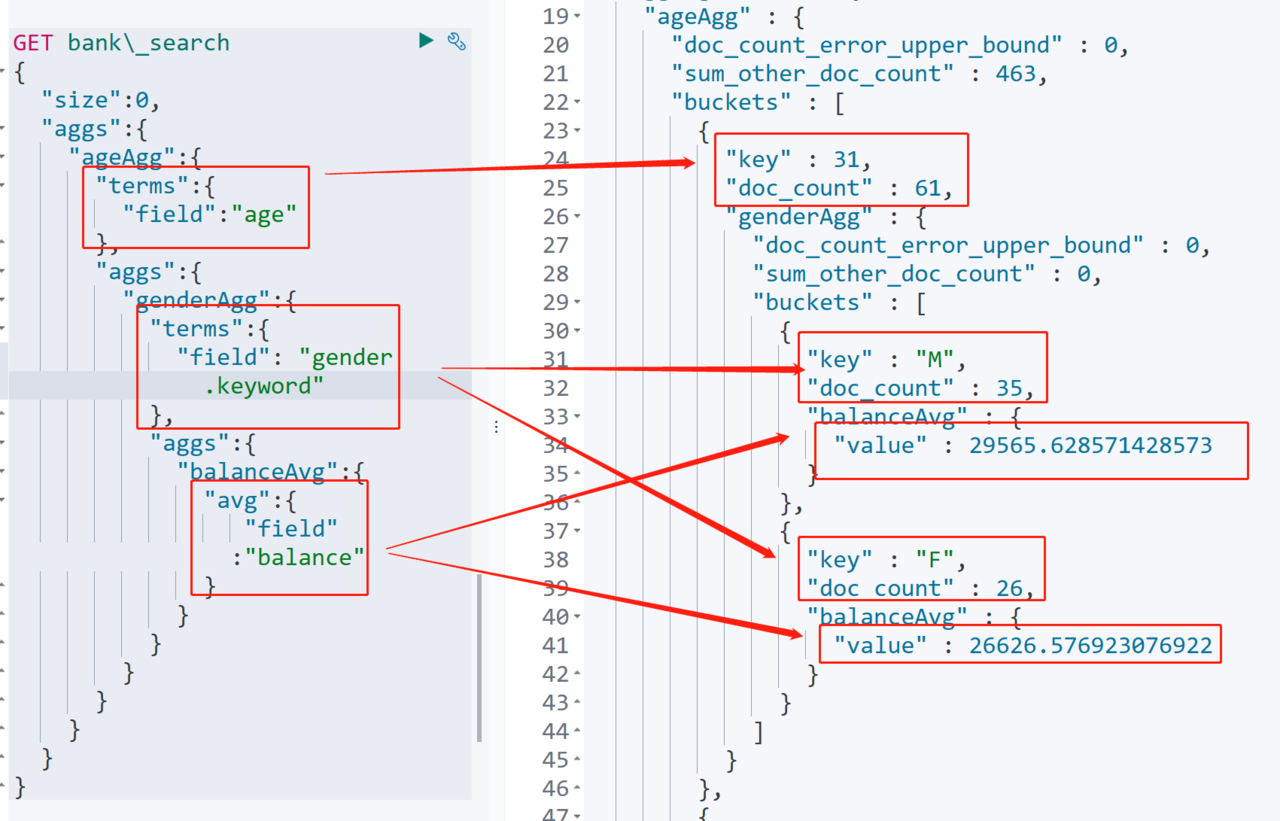
如下查询中,使用桶聚合按照年龄进行了分组,然后再每个年龄分组中,再统计每个年龄的男性和女性数量,并统计男性和女性的平均存款
 wenyl 的个人博客
wenyl 的个人博客