
一、简介
HDFS(Hadoop Distributed File System)是Hadoop下的分布式文件系统具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。
二、架构
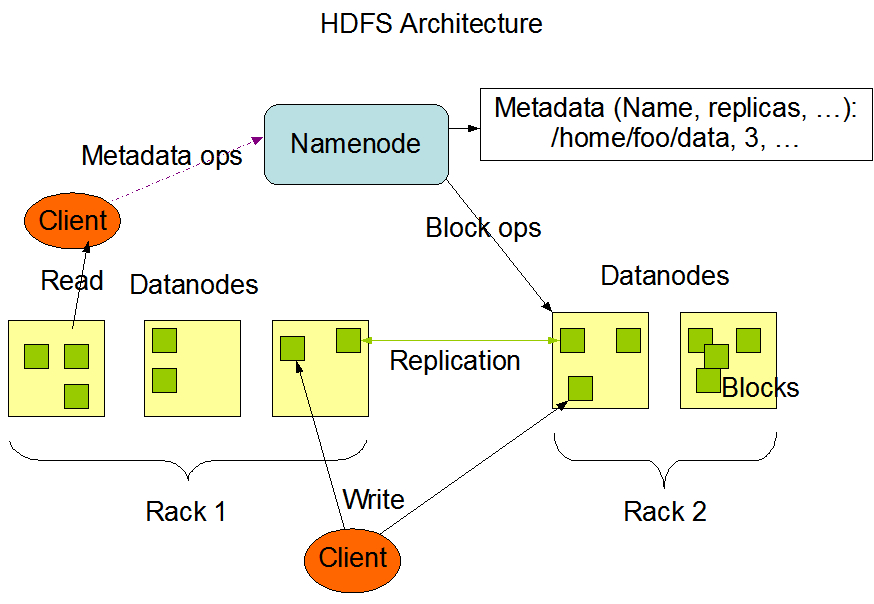
HDFS架构如下所示,主要包含Namenode、client、datanode三个部分,一个HDFS系统,可以有多个client和datanode但是namenode只能有一个
- client客户端包含HDFS的接口,用于访问HDFS的文件
- namenode存储文件名,文件元数据,文件与数据块的对应关系
- datanode是用于存储数据的节点

三、HDFS相关概念
3.1 block-块
3.2 namenode和datanode
| namenode | datanode |
|---|
| 存储元数据 | 存储文件内容 |
| 数据保存在内存中 | 数据保存在磁盘中 |
| 保存文件、block,datanode之间的映射关系 | 维护block id与datanode本地文件的映射关系 |
HDFS只有一个namenode,简化了系统设计,但是会带来以下问题
- 命名空间的限制:namenode节点保存在内存中,namenode保存的数据量受内存空间大小限制
- 吞吐量:HDFS的吞吐量受限与namenode
- 隔离问题:集群中只有一个namenode,如果应用程序使用同一个集群,则无法对应用程序进行隔离
- 集群可用性:namenode故障则集群不可用
3.3 HDFS命名空间管理
- HDFS命名空间包含目录文件和块
- HDFS使用的文件分级体系与linux类似,支持创建、删除目录或文件
- namenode维护文件系统命名空间,记录对名称空间或其属性的任何更改
3.4 通信协议
- 所有的HDFS通信协议都是构建在TCP/IP的基础上
- 客户端通过一个可以配置的端口向namenode发起TCP链接,并使用客户端协议与namenode进行交互
- namenode和datanode之间使用数据节点协议进行交互
- 客户端与datanode之间的交互通过RPC(remote procedure call)来实现,namenode不会主动发起RPC,而是相应来自客户端和datanode的rpc请求
3.5 客户端
- HDFS在部署时,都提供了客户端,HDFS客户端是一个库,包含HDFS文件系统接口
- 客户端支持打开、读取、写入等常规操作,并提供了类似shell的命令行方式来访问HDFS中的数据
- HDFS提供了JAVA API作为应用程序访问文件系统的接口
四、关键特性
4.1 高可用性
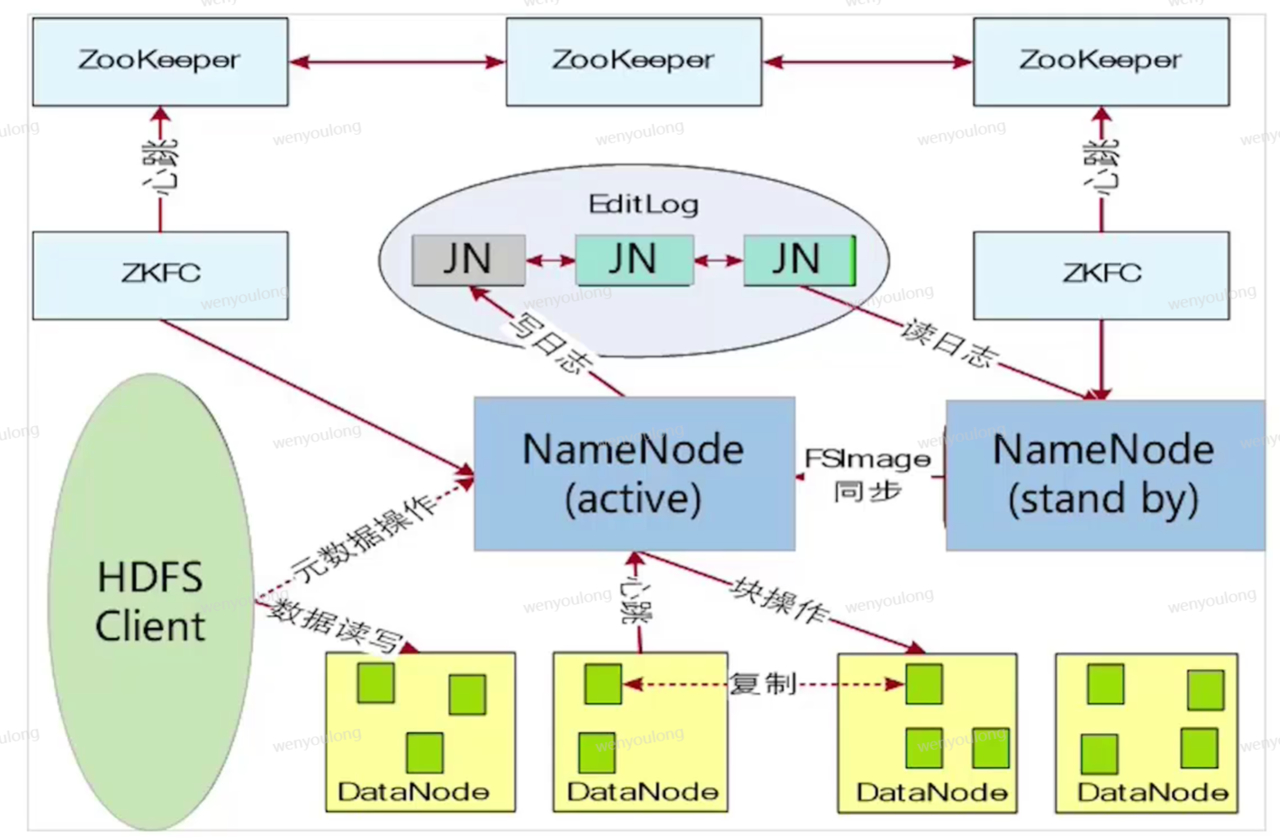
如下图所示,为了解决hdfs单节点的问题,设置了两个namenode一个作为主节点,一个作为备份节点,并通过zookeeper监控namenode运行状况,节点之间通过EditLog日志或FSImage进行同步,namenode通过心跳监测监控datanode运行状况
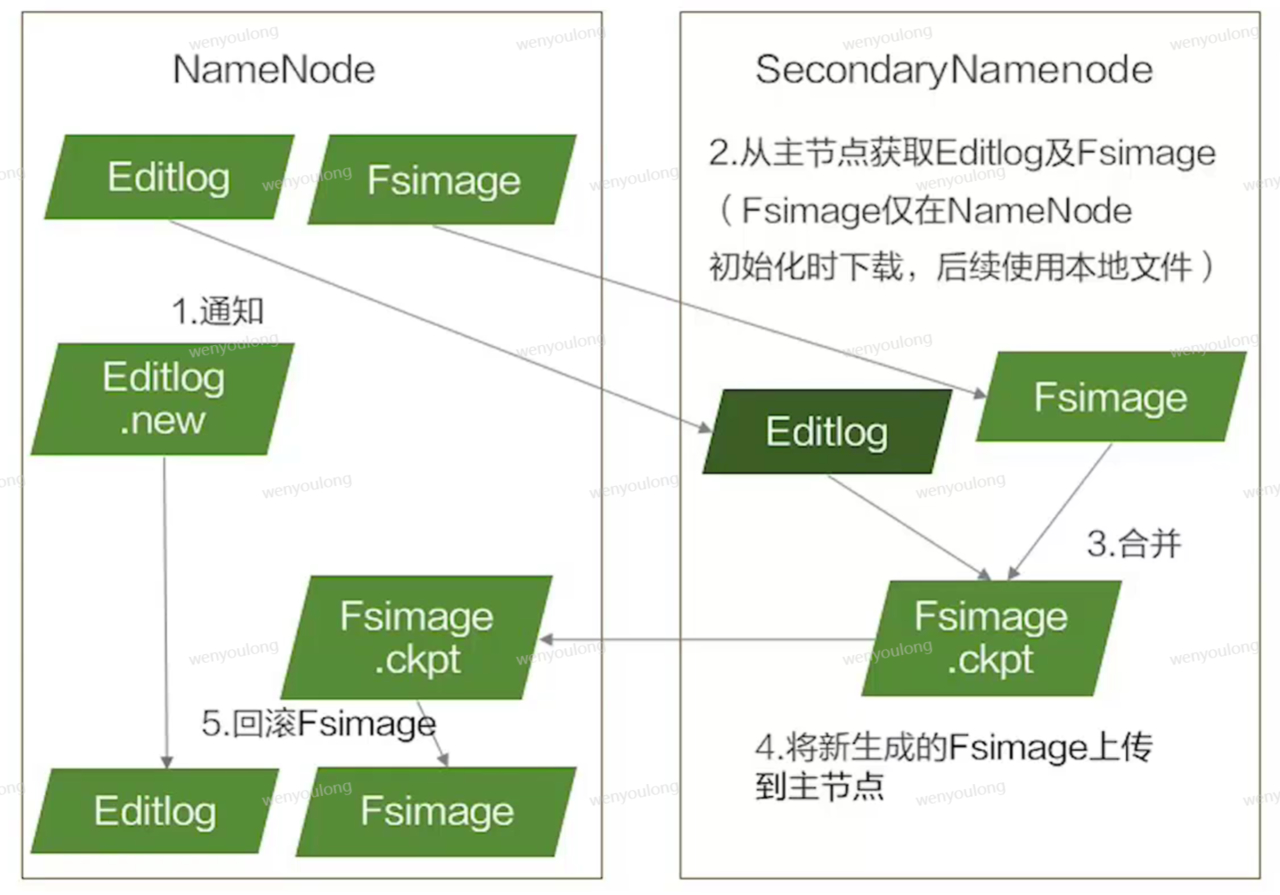
4.2 元数据持久化
元素持久化通过secondaryNamenode(与stand by namenode不是一个组件)实现,secondaryNamenode通知namenode将ediglog和Fsimage发送给到secondaryNamenode时,namenode会在本地创建一个Editlog.new用于记录此时之后发生的元数据变更操作,secondaryNamenode利用接收到的editlog信息对Fsimage中的内容进行更新,得到一个新的Fsimage文件,然后上传到namenode,namenode节点根据新的Fsimage更新自己的Fsimage,然后将Editlog.new中的内容再更新到Fsimage
- Fsimage存储文件系统数,文件夹、文件元素信息
- Editlog中存储对元数据的修改信息
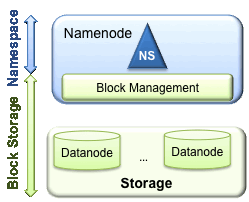
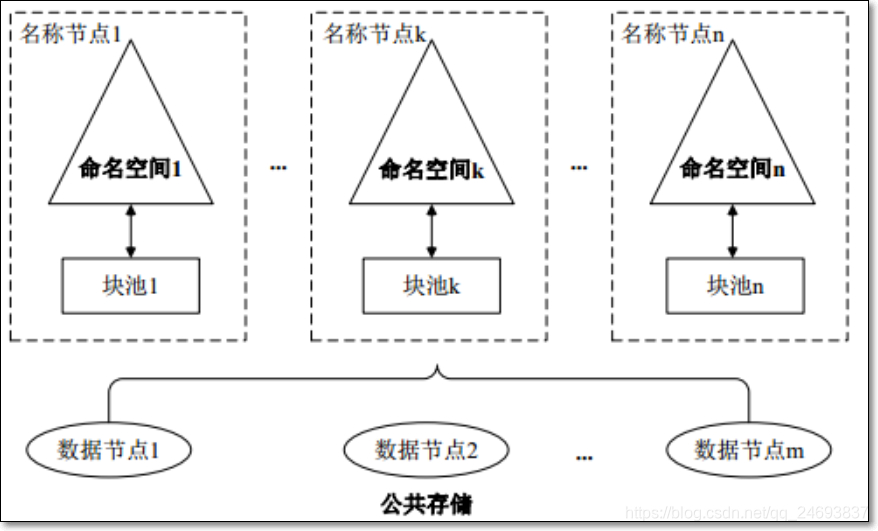
4.3 HDFS联邦(Federation)
HDFS有两个主要层如下图所示:
-
namespace
- 由文件和块组成
- 支持所有与命名空间相关的文件系统操作,如新增、删除文件或目录
-
块存储服务
- 块管理
- 通过处理注册和周期性心跳来提供数据节点群集成员身份。
- 处理块报告并维护块的位置。
- 支持创建、删除、修改、获取区块位置等区块相关操作。
- 管理副本放置、复制不足块的块复制,并删除过度复制的块。
- 存储 - 由数据节点通过在本地文件系统上存储块并允许读/写访问来提供
一个HDFS集群只有一个Namenode会带来一些其他问题(详见3.2的描述),HDFS联邦将多个HDFS集群合并为有多个namenode的集群,这样就可以解决系统的数据权限问题,系统找到自己的文件所在的namenode访问即可
- HDFS联邦中,设计了多个命名空间;每个命名空间有一个namenode或一主一备两个namenode,使得HDFS的命名服务能够水平扩展
- 这些namenode分别进行各自命名空间namespace和块的管理,相互独立,不需要彼此协调
- 每个datanode要向集群中所有的namenode注册,并周期性的向所有namenode发送心跳信息和块信息,报告自己的状态
- HDFS联邦每个相互独立的namenode对应一个独立的命名空间
- 每一个命名空间管理属于自己的一组块,这些属于同一命名空间的块对应一个“块池”的概念
- 每个datanode会为所有块池提供块的存储,块池中的各个块实际上是存储在不同datanode中的
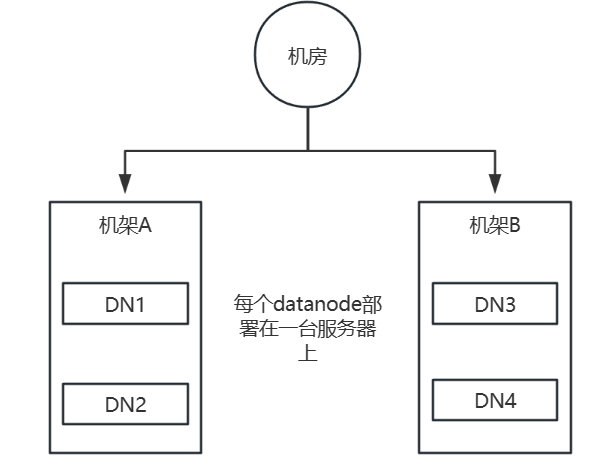
4.4 数据副本机制
有一机房如下所示,有两个机架,每个机架有两台服务器,每台服务器都部署了一个datanode,,数据副本数量可以设置,集群环境默认三个
- 来自外部的客户端
- 第一个副本随机选择一台机器,如DN1
- 第二个副本随机选择一个跟DN1在同一个机架上的服务器,如DN2
- 第三个副本随机选择另一个机架下的服务器,如DN3
- 请求方来自内部的datanode服务器,如DN3
- 第一个副本就选择存放在DN3
- 第二个副本随机选择一个跟DN3同属一个机架的服务器,如DN4
- 第三个副本随机选择另一个机架下的服务器,如DN1
4.5 HDFS数据完整性保障
HDFS对各组件的失效,做了可靠性处理
- 重建失效数据盘的副本数据
- datanode和namenode周期上报失效时(心跳检测),Namenode发起副本重建动作以恢复
- 集群数据均衡
- HDFS架构设计了数据均衡机制,保证数据在datanode上的分布时平均的
- 元数据可靠性保证
- 采用日志机制存储元数据,同时元数据存放在主备namenode上
- 实现了快照机制,保证数据恢复
- 安全模式
- HDFS在datanode故障时,硬盘故障时,能防止故障扩散,此时客户端可以读数据,但是不能写数据
4.6 其他特性
- 空间回收机制
- 数据组织
- 访问方式
- 提供Java API,HTTP方式,SHELL方式访问HDFS数据
4.7 HDFS3.0新特性
- 支持HDFS中的纠删码Erasure Encoding,代替了副本机制
- 检错码 识别错误
- 纠错码 识别纠正错误
- 纠删码 识别纠正消除错误,代替了副本机制
- 基于HDFS路由器的联合,添加了一个RPC的路由层,提供多个HDFS命令空间的联合视图,简化了HDFS客户端对联合集群的访问
- 支持多个NameNode(主备机制,一个active,多个stand by)
- DataNode内部添加了负载均衡Disk Balancer
五、HDFS数据读写流程
5.1 写数据流程
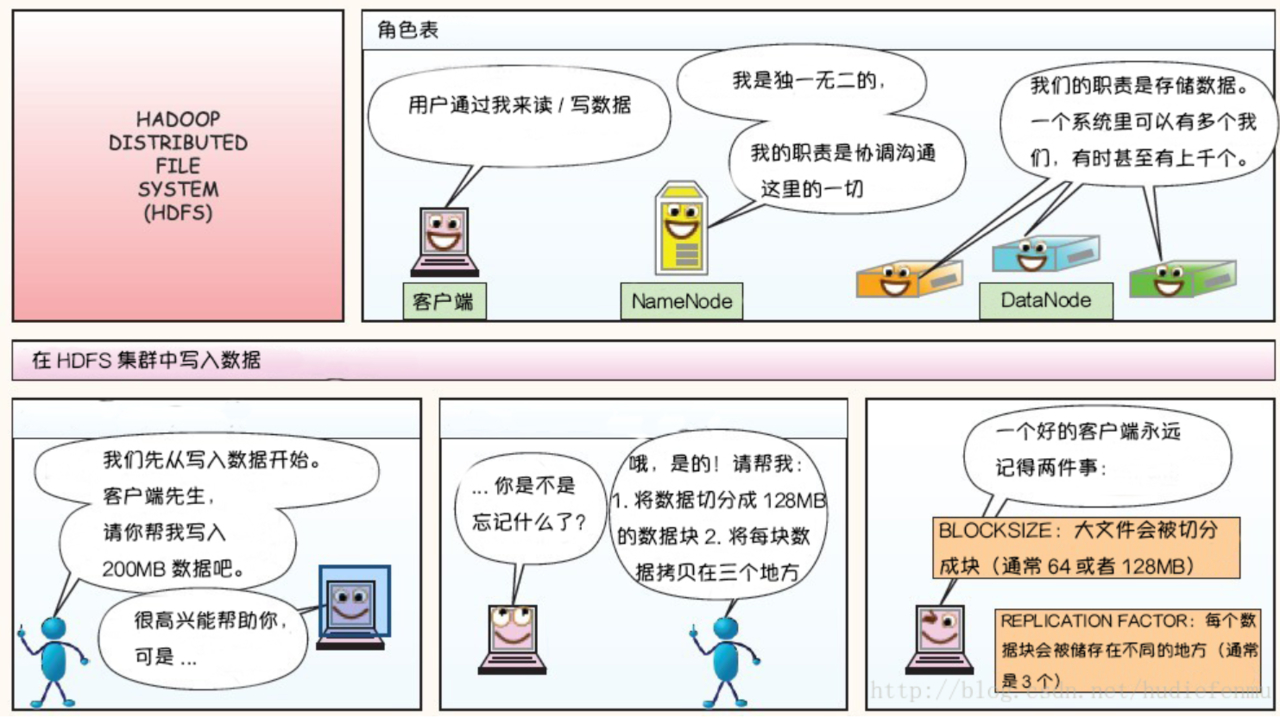
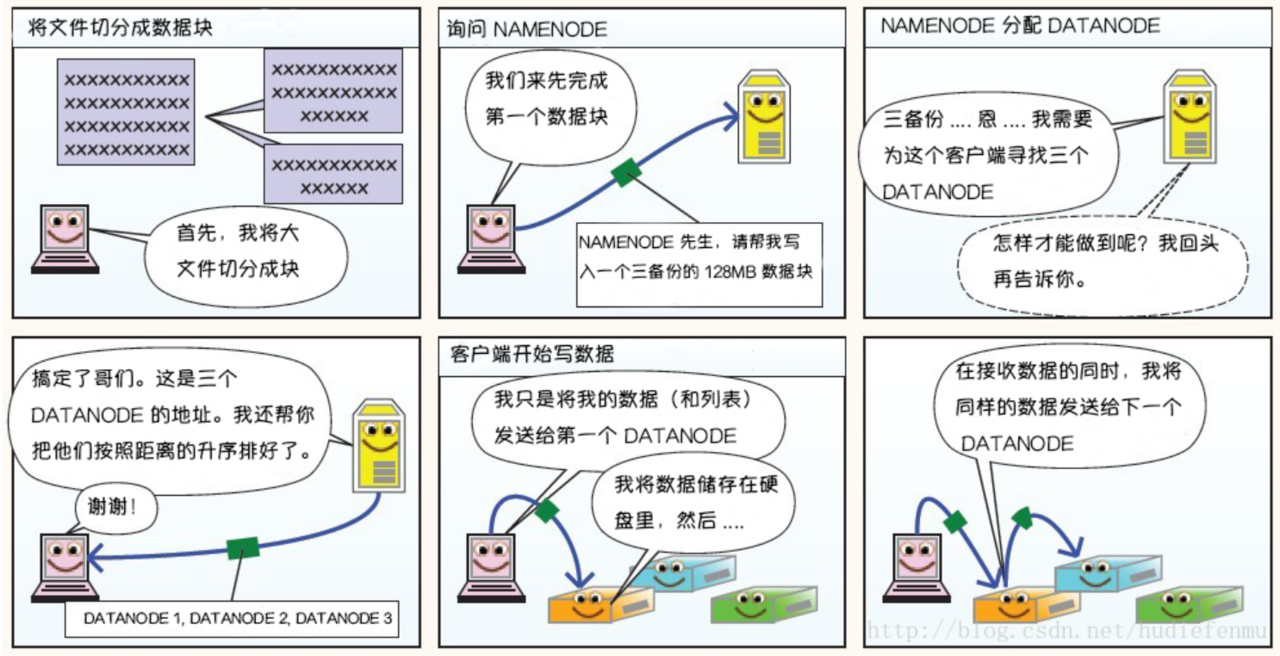
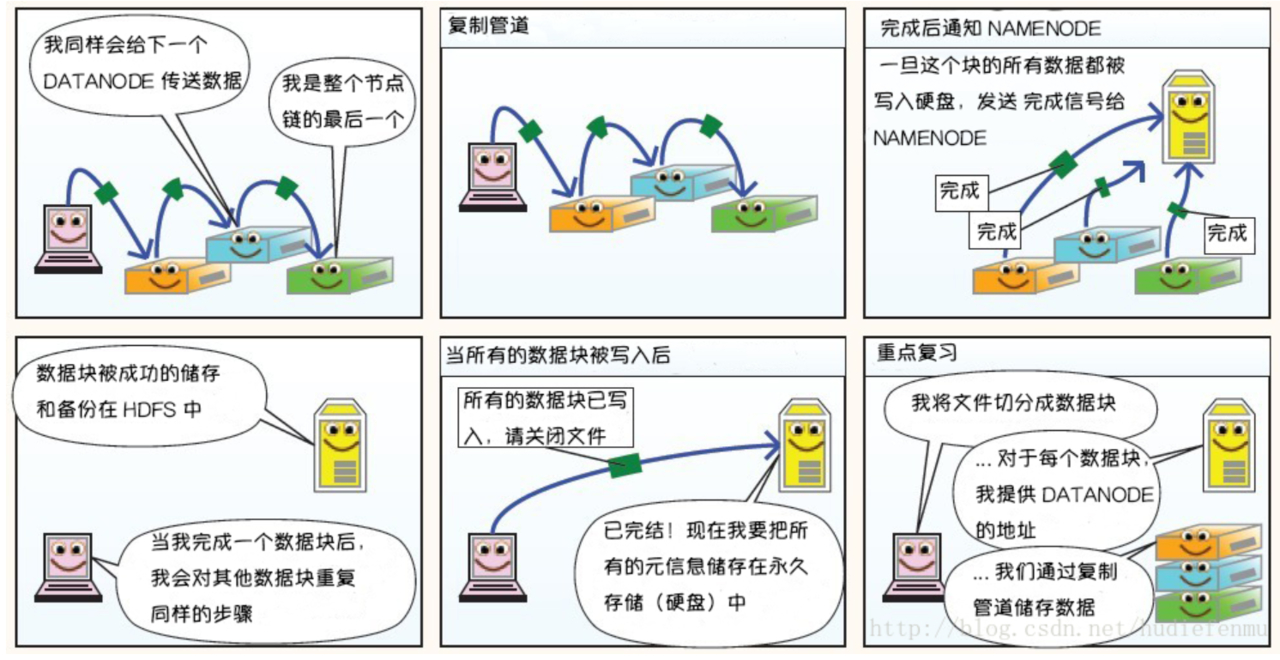
5.2 读数据流程
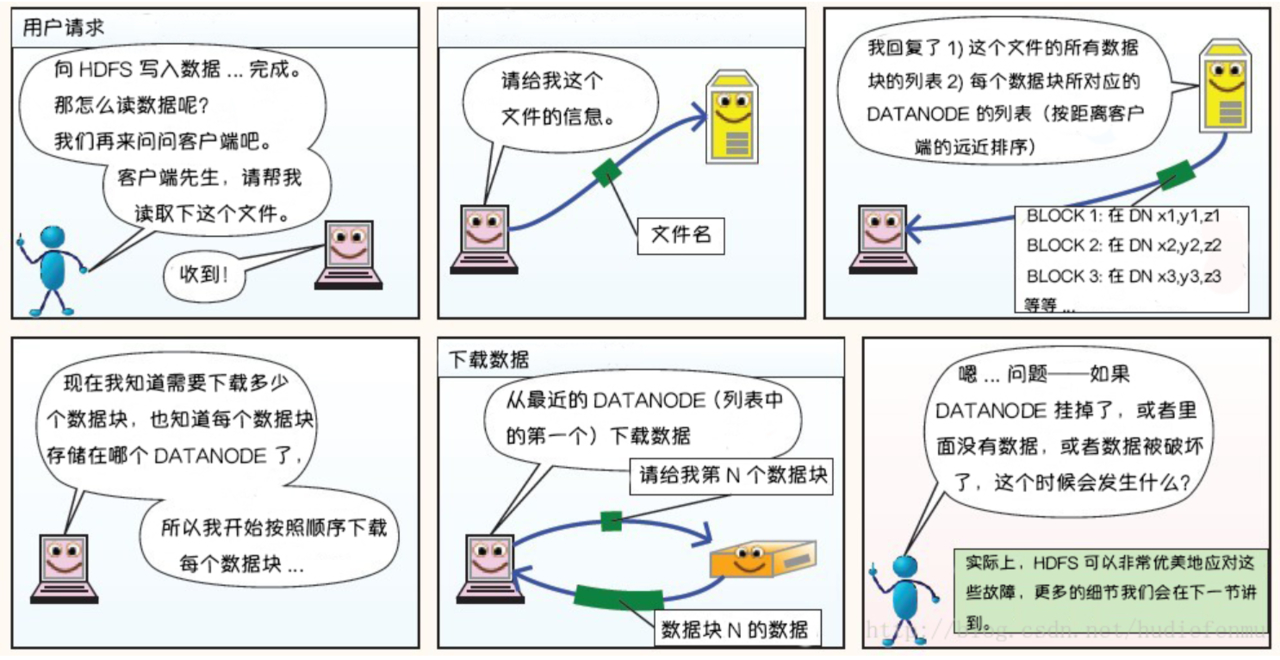
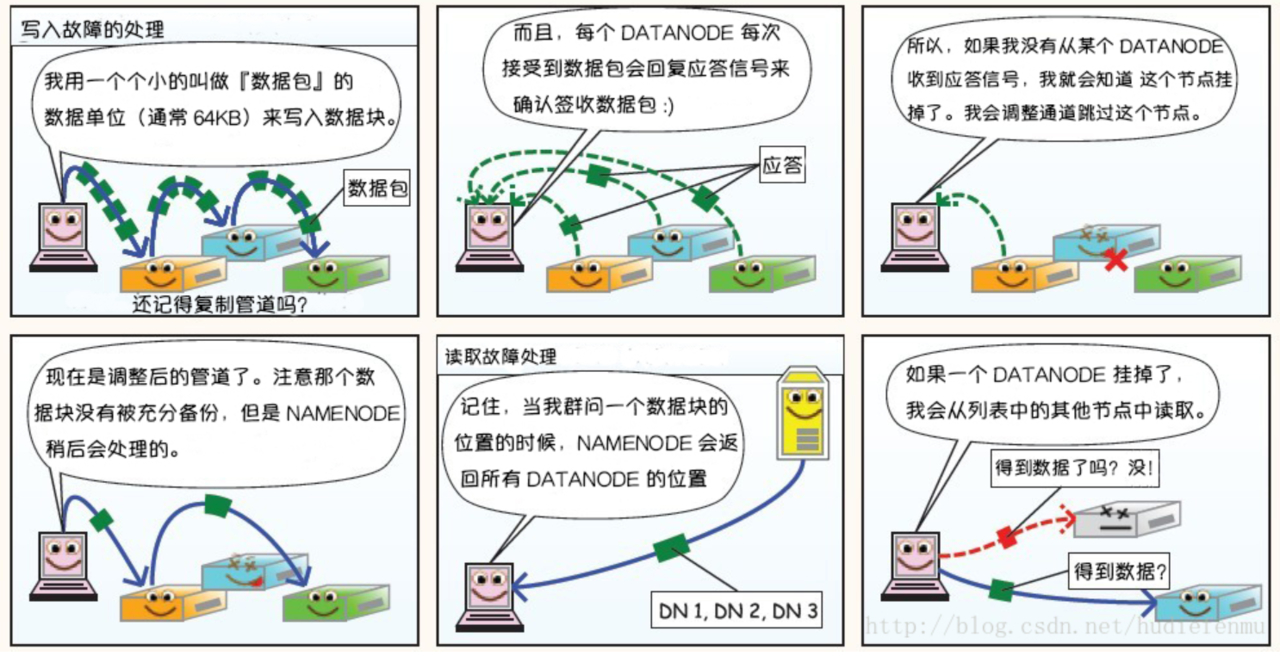
5.3 读写数据故障处理
参考
HDFS高可用与联邦机制_hdfs联邦机制下一些dn连接不到ns4-CSDN博客
Apache Hadoop 3.3.6 – HDFS Federation
HDFS分布式文件系统和ZooKeeper_在线课程_华为云开发者学堂_云计算培训-华为云 (huaweicloud.com)
BigData-Notes/notes/Hadoop-HDFS.md at master · heibaiying/BigData-Notes (github.com)
 wenyl 的个人博客
wenyl 的个人博客