
一、概述
Zookeeper分布式服务框架是一个分布式应用程序协调服务,提供分布式、高可用性的协调服务能力;
安全模式下Zookeeper依赖Kerberos和LdapServer进行安全认证,非安全模式则不依赖于Kerberos和LdapServer。Zookeeper作为底层组件被上层组件使用并依赖,如Kafka,HDFS,HBase,Storm等
二、体系结构
2.1 服务架构
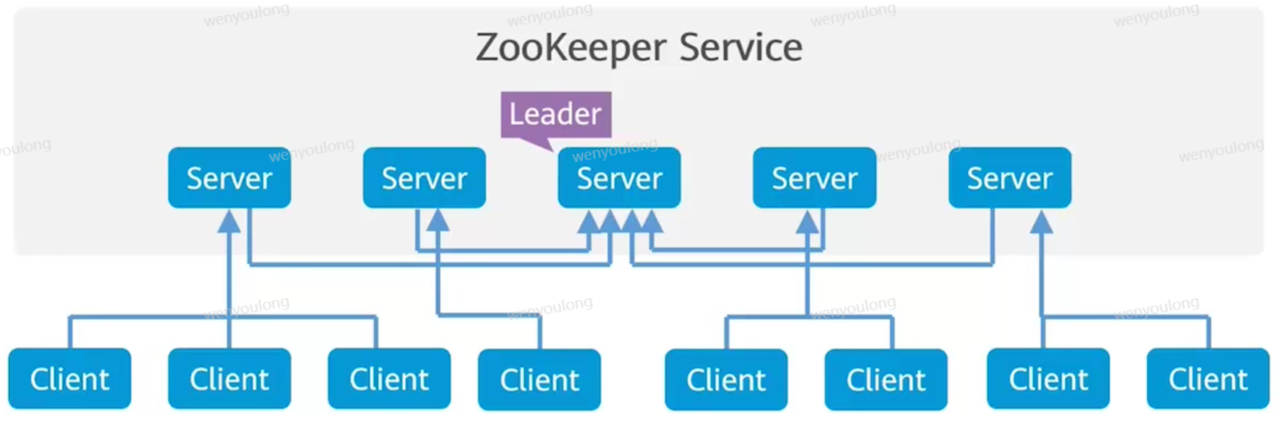
- zookeeper集群是由一组server节点组成,这一组server节点中只有一个leader节点,其他节点都是follower
- 启动时选举出leader,各个节点互相投票,票数最多的节点选举为leader
- zookeeper使用自定义的原子消息协议,保证了整个系统中的节点数据得一致性
- leader节点在接收到数据变更请求后,先写磁盘再写内存
2.2 容灾能力
- Zookeeper完成选举就可以对外提供服务
- 对n个实例得服务
- n为奇数时,假定n=2x+1,则成为leader得节点需要获得x+1票,容灾能力为x
- n为偶数时,假定n=2x+2,则成为leader得节点需要获得x+2票(大于一半),容灾能力为x
2.3 关键特性
- 最终一致性:各个server对外展示得都是一个视图
- 实时性:保证客户端将在一个时间间隔范围内获得服务器得更新信息,或者服务器失效得信息
- 可靠性:一条消息被一个server接收,他将会被所有server接收
- 等待无关性:慢的或失效的client不会干预快速的client的请求,使得每个client都能有效等待
- 原子性:更新要么成功要么失败
- 顺序一致性:客户端所发送的更新会按照他们发送的顺序进行应用
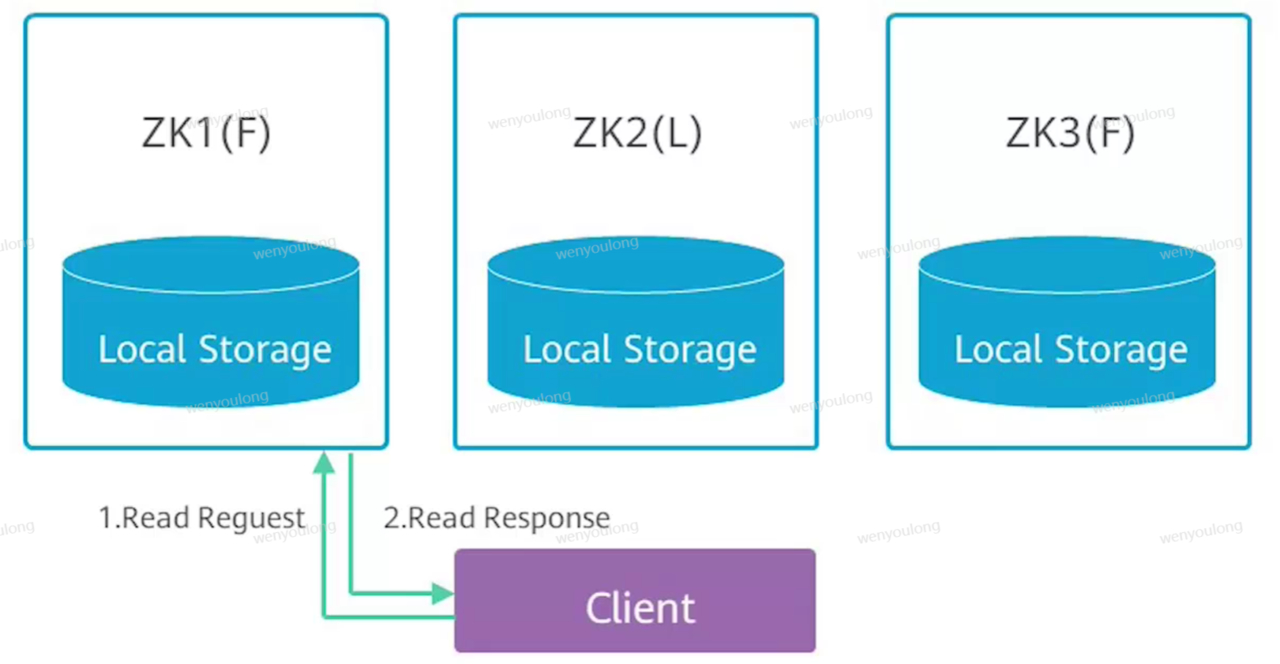
2.3 读特性
由zookeeper的一致性可知,客户端无论连接到哪一个server,获取的均是同一个视图,所以读操作可以在客户端与任意节点间完成
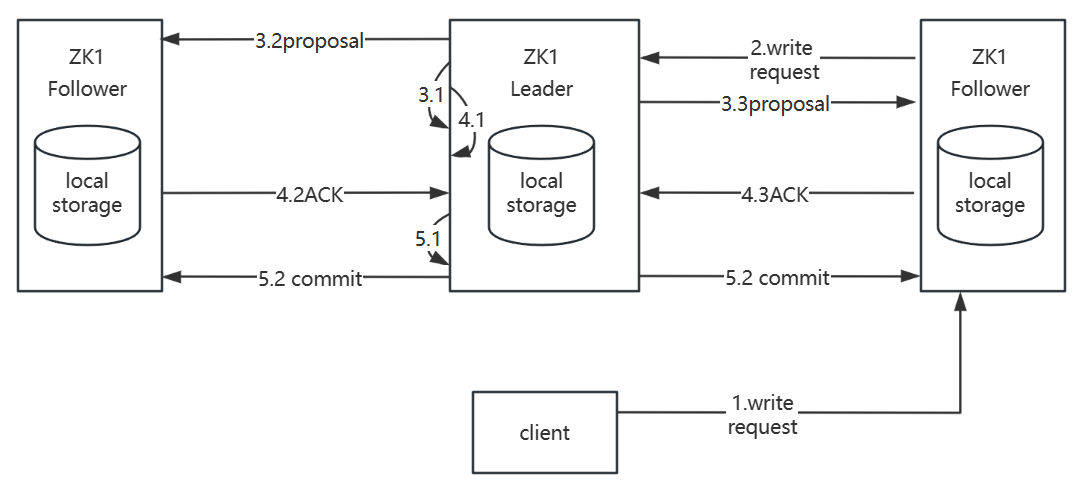
2.4 写特性
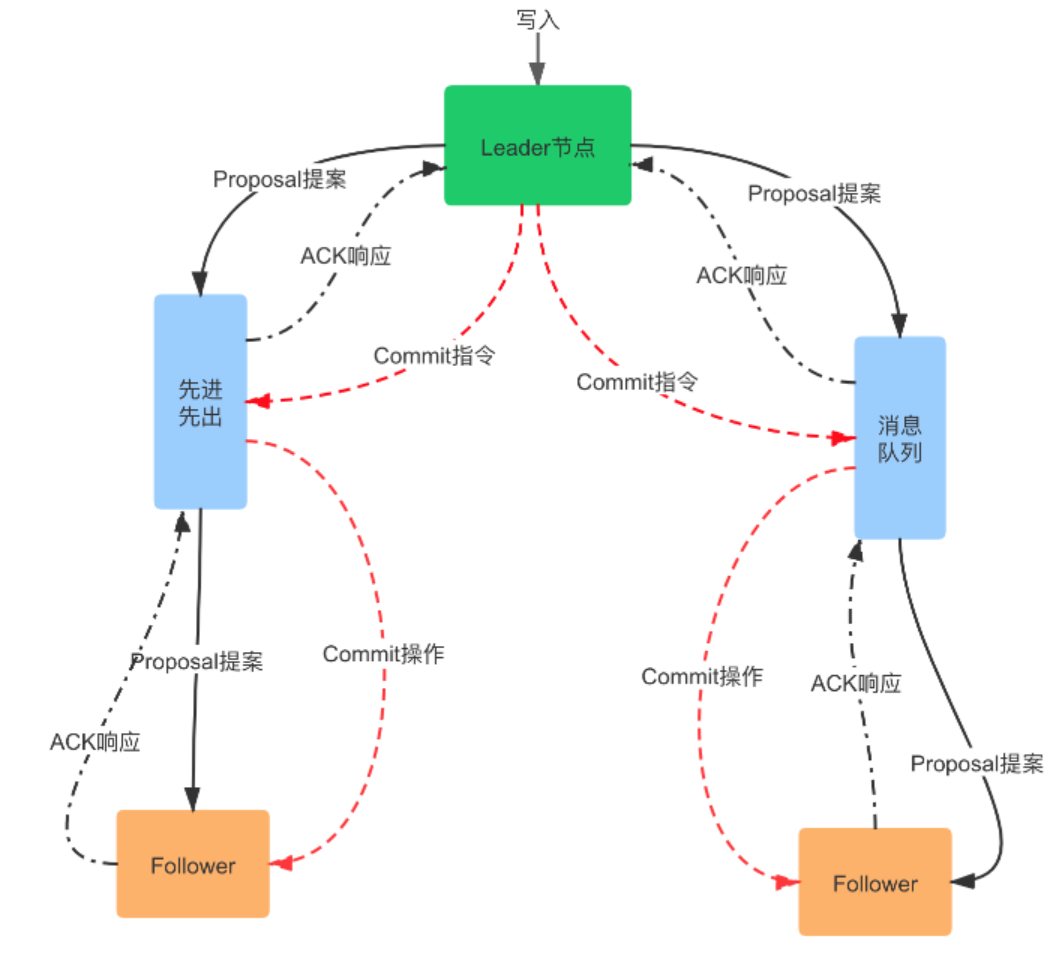
如下两图分别展示了从follower和leader节点写数据的流程,整体流程如下
- 客户端发起写请求
- 请求如果被follower节点接收,则先将请求发送至leader节点,Leader 会将写请求包装成 Proposal 事务,并添加一个递增事务 ID,也就是 Zxid,Zxid 是单调递增的,以保证每个消息的先后顺序
- leader广播这个 Proposal 事务,Leader 节点和 Follower 节点是解耦的,通信都会经过一个先进先出的消息队列,Leader 会为每一个 Follower 服务器分配一个单独的 FIFO 队列,然后把 Proposal 放到队列中
- Follower 节点收到对应的 Proposal 之后会把它持久到磁盘上,当完全写入之后,发一个 ACK 给 Leader
- 当 Leader 收到超过半数 Follower 机器的 ack 之后,会提交本地机器上的事务,同时开始广播 commit, Follower 收到 commit 之后,完成各自的事务提交
参考
HDFS分布式文件系统和ZooKeeper_在线课程_华为云开发者学堂_云计算培训-华为云 (huaweicloud.com)
ZooKeeper 如何保证数据一致性 - sw_kong - 博客园 (cnblogs.com)
 wenyl 的个人博客
wenyl 的个人博客