
Index of /hadoop/common (apache.org)
在这个地址中下载hadoop安装包,选择一个稳定版或者自己需要的版本下载即可
我下载了稳定版的hadoop,链接如下
https://dlcdn.apache.org/hadoop/common/stable/hadoop-3.3.6.tar.gz
Hadoop Java Versions - Hadoop - Apache Software Foundation
注意里面标注了有几个版本的java8,与hadoop可能存在一些兼容问题
这是我下载的版本
配置ssh免密登录,参考SSH免密登录 - 问尤龙の时光 (wenyoulong.com)
将jdk和hadoop都上传到服务器/opt目录下
jdk安装参考linux安装Java开发环境 - 问尤龙の时光 (wenyoulong.com)
执行解压命令
tar -zxvf hadoop-3.3.6.tar.gz
输入命令如下就回输出hadoop得命令语法
/opt/hadoop-3.3.6/bin/hadoop
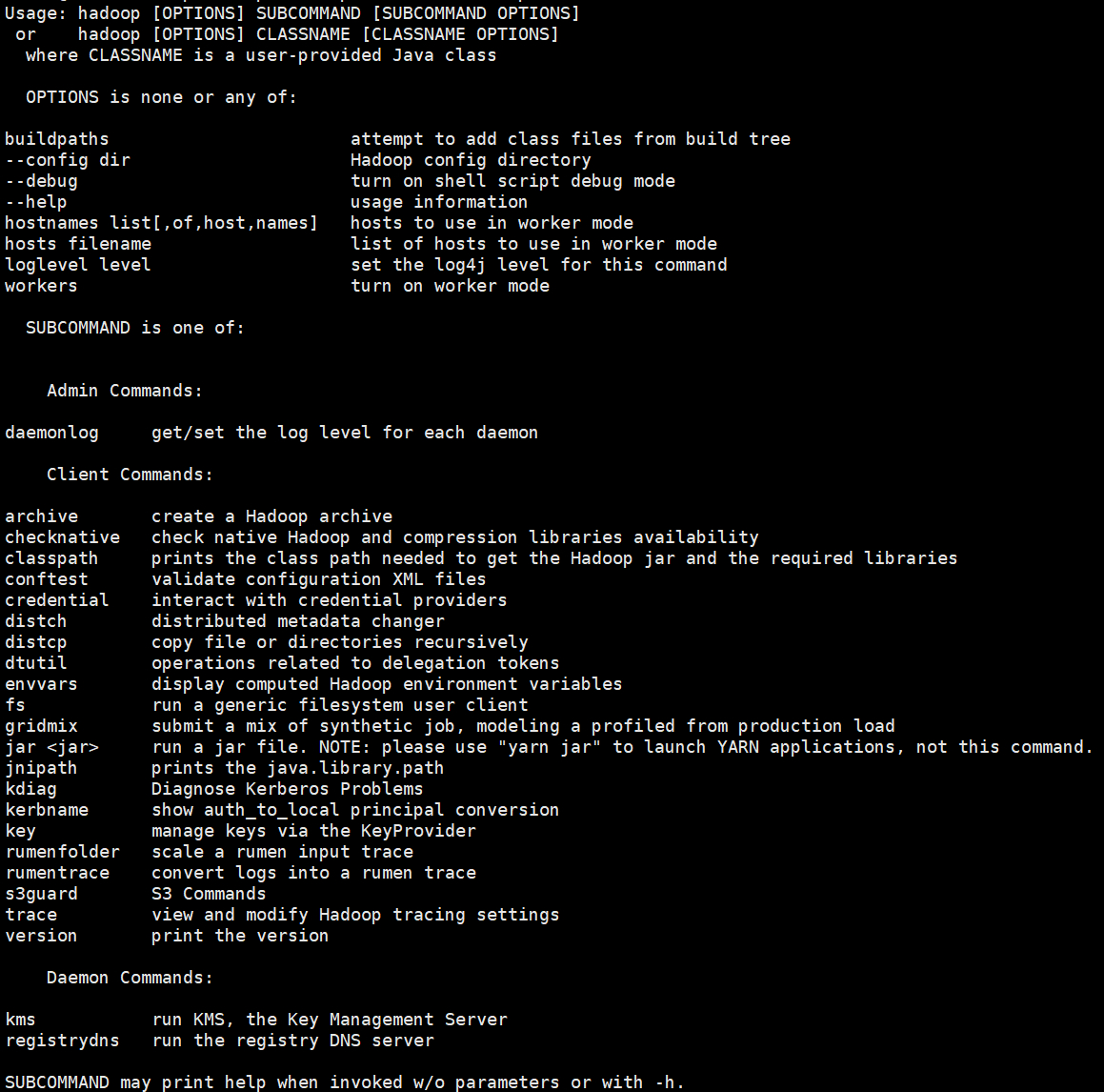
将hadoop得bin目录配置道环境变量
vi /etc/profile
输入内容
export HADOOP_HOME=/opt/hadoop-3.3.6
export PATH=PATH:PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行命令
source /etc/profile
执行命令
hadoop version
提示如下

在hadoop-env.sh中配置jdk位置
vi /opt/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
添加配置
export JAVA_HOME=/opt/jdk1.8.0_391/
hadoop可以在伪分布式的单节点上运行,配置如下
vi /opt/hadoop-3.3.6/etc/hadoop/core-site.xml
输入配置内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
vi /opt/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
输入配置内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
vi /opt/hadoop-3.3.6/libexec/hdfs-config.sh
添加配置
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
/opt/hadoop-3.3.6/bin/hdfs namenode -format
注意这个命令只能执行一次,执行会生成一个ClusterID,如果重复执行会导致之前的数据不可用,datanode无法启动,如果重复执行了,可以通过如下步骤重新格式化
/opt/hadoop-3.3.6/sbin/stop-dfs.sh
rm -Rf /tmp/hadoop-root/*
/opt/hadoop-3.3.6/bin/hdfs namenode -format
这里删除了tmp目录下的hadoop-root目录下所有内容,我是用root用户操作,所以是hadoop-root,对应替换成自己的用户名即可
关闭防火墙
systemctl stop firewalld.service
开机不启动防火墙
systemctl disable firewalld.service
/opt/hadoop-3.3.6/sbin/start-dfs.sh
启动后通过jps查看有服务如下即可
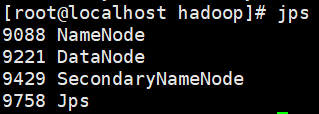
然后浏览器访问namenode节点的9870端口即可
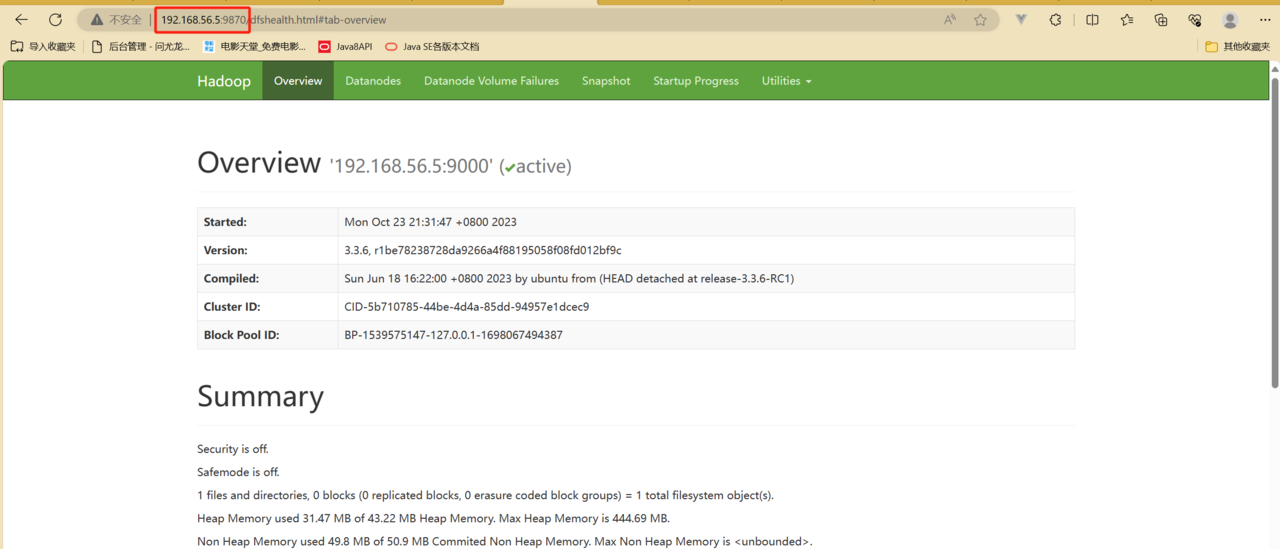
4.5除了4.5.1后面都在192.168.56.5上执行
192.168.56.5上执行 hostnamectl set-hostname master
192.168.56.6上执行 hostnamectl set-hostname slave1
192.168.56.7上执行 hostnamectl set-hostname slave2
| IP | 192.168.56.5 | 192.168.56.6 | 192.168.56.7 |
|---|---|---|---|
| 主机名 | master | slave1 | slave1 |
编辑文件
vi /etc/hosts
新增内容如下
192.168.56.5 master
192.168.56.6 slave1
192.168.56.7 slave2
| IP | master | slave1 | slave2 |
|---|---|---|---|
| 运行服务 | NameNode,ResourceManager, SecondaryNameNode | DataNode, NodeManager | DataNode, NodeManager |
vi /opt/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
添加配置如下,这里指定了用户,我都是用的root用户操作,所以都设置成了root
export JAVA_HOME=/opt/jdk1.8.0_391/
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
指定namenode地址、指定hadoop数据存储目录
vi /opt/hadoop-3.3.6/etc/hadoop/core-site.xml
配置内容如下
<!-- 系统中默认的文件系统URI -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 临时文件存放位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop-3.3.6/tmp</value>
</property>
创建对应目录
mkdir -p /opt/data/hadoop-3.3.6/tmp
该文件用户对namenode和secondaryNamenode进行配置
vi /opt/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
新增配置如下
<!-- HDFS文件备份数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- namenode存放的位置,老版本是用dfs.name.dir -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/data/hadoop-3.3.6/name</value>
</property>
<!-- datanode存放的位置,老版本是dfs.data.dir -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/data/hadoop-3.3.6/data</value>
</property>
<!-- 关闭文件上传权限检查 -->
<property>
<name>dfs.permissions.enalbed</name>
<value>false</value>
</property>
<!-- namenode运行在哪儿节点,默认是0.0.0.0:9870,在hadoop3.x中端口从原先的50070改为了9870 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- secondarynamenode运行在哪个节点,默认0.0.0.0:9868 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
创建对应目录
mkdir -p /opt/data/hadoop-3.3.6/name
mkdir -p /opt/data/hadoop-3.3.6/data
对resourceManager和node
vi /opt/hadoop-3.3.6/etc/hadoop/yarn-site.xml
新增配置内容如下
<!-- 指定resourceManager位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- nodemanager获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 关闭虚拟内存检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
vi /opt/hadoop-3.3.6/etc/hadoop/mapred-site.xml
新增配置如下
<!-- 设置mapreduce在yarn平台上运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置mapreduce运行库,不配置会报错,报错内容见4.5.12小节 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
vi /opt/hadoop-3.3.6/etc/hadoop/workers
新增配置如下
slave1
slave2
将192.168.56.5上配置好的jdk文件和hadoop文件传输到192.168.56.6和192.168.56.7
scp -r /opt/jdk1.8.0_391/ root@slave1:/opt
scp -r /opt/hadoop-3.3.6/ root@slave1:/opt
scp -r /opt/jdk1.8.0_391/ root@slave2:/opt
scp -r /opt/hadoop-3.3.6/ root@slave2:/opt
scp /etc/profile root@slave1:/etc/
scp /etc/profile root@slave2:/etc/
scp /etc/hosts root@slave1:/etc/
scp /etc/hosts root@slave2:/etc/
格式化文件系统
/opt/hadoop-3.3.6/bin/hdfs namenode -format
执行启动脚本
/opt/hadoop-3.3.6/sbin/start-dfs.sh
/opt/hadoop-3.3.6/sbin/start-yarn.sh
使用jps查看服务均已启动
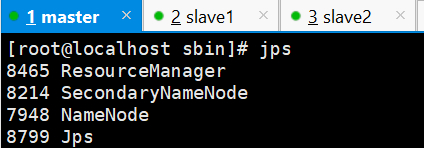
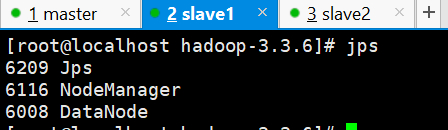
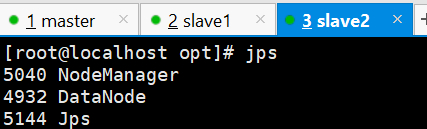
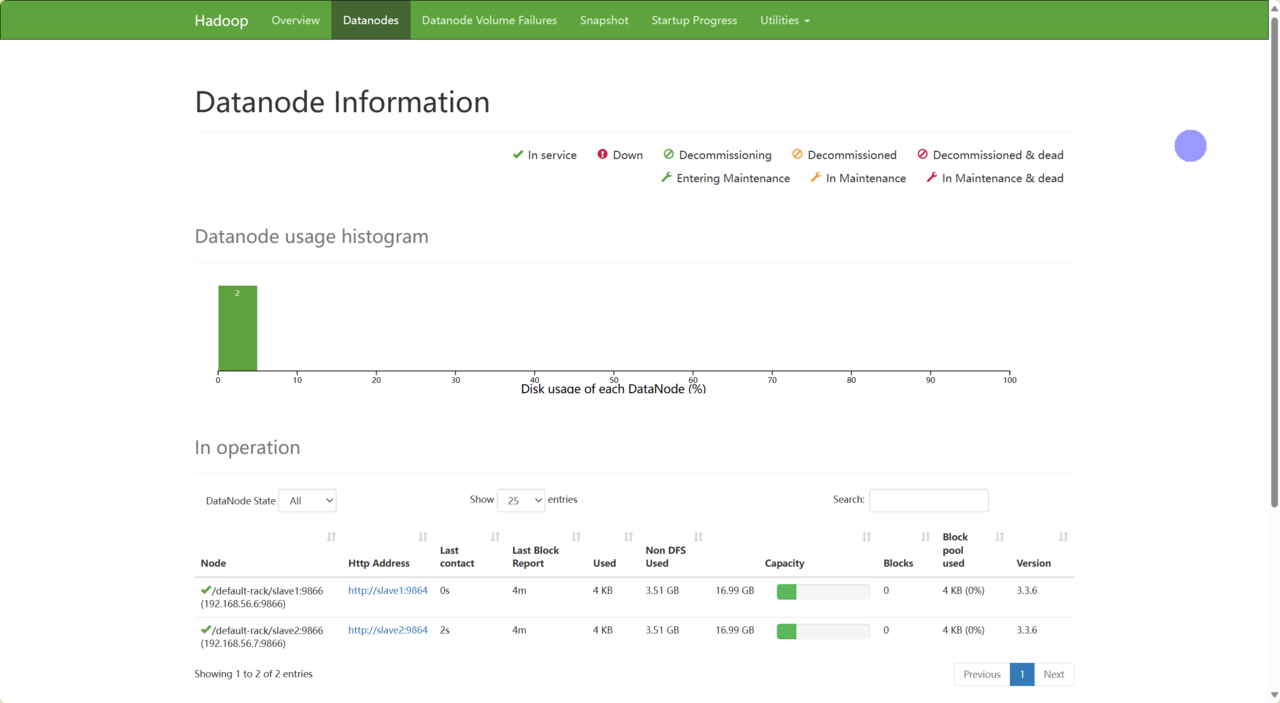
宿主机访问虚拟机192.168.56.5:9870,进去就能看到节点信息
以词频统计为例,再master虚拟机上创建文件
vi /opt/words.txt
内容如下
hadoop hdfs hdfs hadoop
mapreduce mapreduce hadoop
hdfs hadoop yarn yarn
然后执行命令
# 在hdfs上创建文件夹
hdfs dfs -mkdir /input
# 把words.txt上传到hdfs的input文件夹中
hdfs dfs -put words.txt /input/
执行mapreduce任务
hadoop jar /opt/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /input/ /output
执行后报错如下,提示我们mapred-site.xml要包含内容
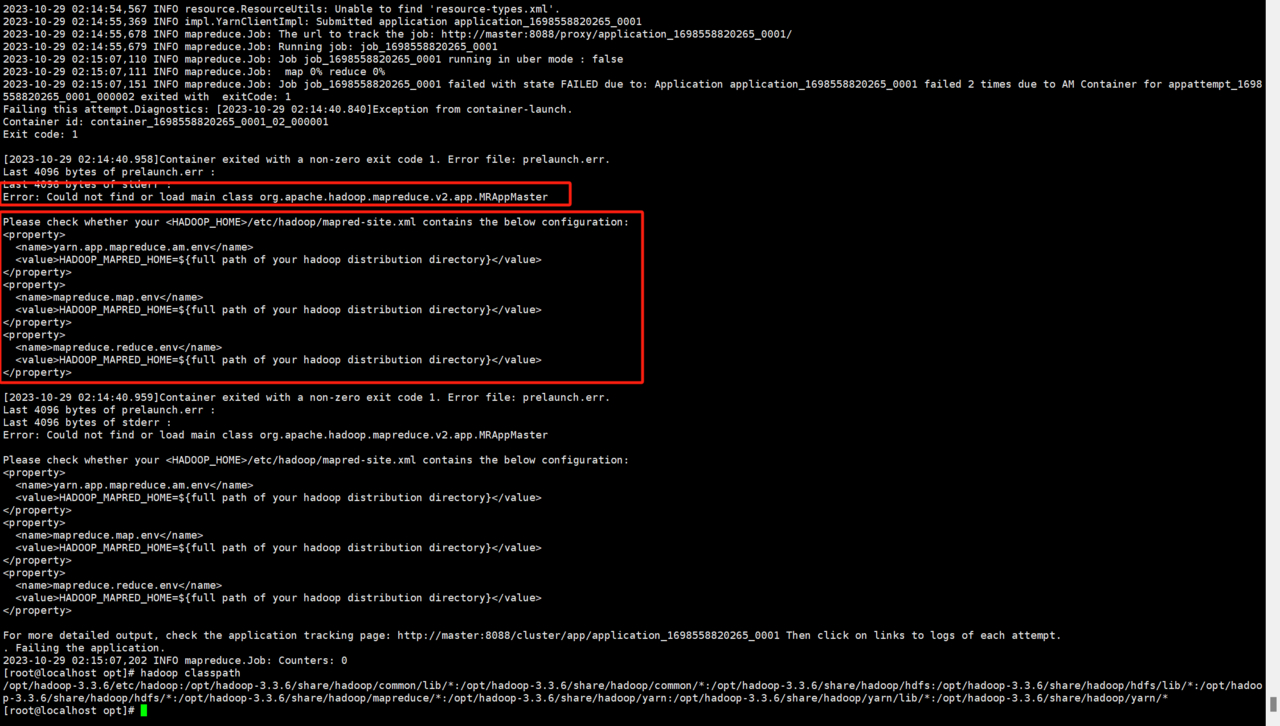
修改mapred-site.xml文件配置
vi /opt/hadoop-3.3.6/etc/hadoop/mapred-site.xml
新增内容
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
停止hadoop服务
/opt/hadoop-3.3.6/sbin/stop-yarn.sh
/opt/hadoop-3.3.6/sbin/stop-dfs.sh
将mapred-site.xml发送到slave1和slave2
scp /opt/hadoop-3.3.6/etc/hadoop/mapred-site.xml root@slave1:/opt/hadoop-3.3.6/etc/hadoop
scp /opt/hadoop-3.3.6/etc/hadoop/mapred-site.xml root@slave2:/opt/hadoop-3.3.6/etc/hadoop
启动Hadoop集群
/opt/hadoop-3.3.6/sbin/start-dfs.sh
/opt/hadoop-3.3.6/sbin/start-yarn.sh
重新执行mapreduce任务
hadoop jar /opt/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /input/ /output
看到执行成功
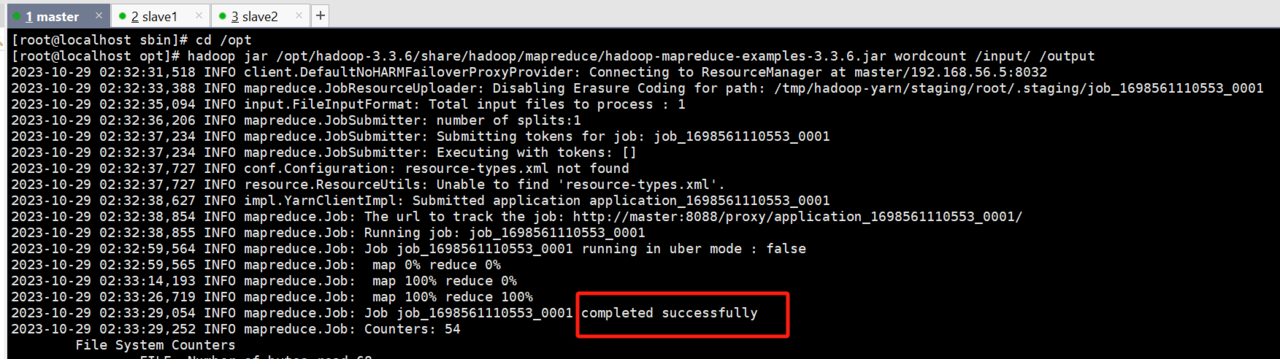
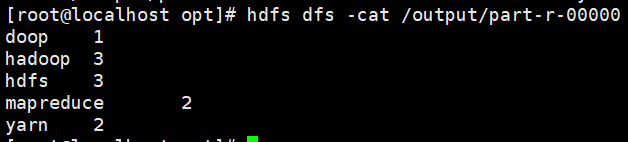
执行命令查看输出的结果
hdfs dfs -ls /output

hdfs dfs -cat /output/part-r-00000
输出结果如下
【精选】hadoop-3.3.3完全分布式集群搭建_hadoop3.3.3-CSDN博客
BigData-Notes/notes/installation/Hadoop集群环境搭建.md at master · heibaiying/BigData-Notes (github.com)
 wenyl 的个人博客
wenyl 的个人博客